version history
|
A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z
| This document uses XHTML/Unicode to
format the display. If you think special symbols are not displaying
correctly, see our guide Displaying
Special Characters. | |
last substantive content
change
|
Inductive Logic
An inductive logic is a system of reasoning that extends deductive logic to
less-than-certain inferences. In a valid deductive argument the premises
logically entail the conclusion, where such entailment means that the
truth of the premises provides a guarantee of the truth of the
conclusion. Similarly, in a good inductive argument the premises should provide
some degree of support for the conclusion, where such support means
that the truth of the premises indicates with some degree of strength
that the conclusion is true. Presumably, if the logic of good inductive
arguments is to be of any real value, the measure of support it articulates
should meet the following condition:
Criterion of Adequacy (CoA):
As evidence
accumulates, the degree to which the collection of true evidence
statements comes to support a hypothesis, as measured by the logic,
should tend to indicate that false hypotheses are probably false and that true
hypotheses are probably true.
This article will primarily focus on the kind of the approach to inductive
logic most widely studied by philosophers and logicians in recent years. These
logics apply classical probability theory to sentences to represent a measure of
the degree to which evidence statements support hypotheses. This kind of
approach usually draws on Bayes's theorem, which is a theorem of probability
theory, to articulate how the implications of hypotheses about evidence
claims redound to the credit or discredit of the hypotheses. We will
examine the extent to which this kind of logic may pass muster as an adequate
logic of evidential support, especially in regard to the testing of scientific
hypotheses. In particular, we see how such a logic may be shown to satisfy the
Criterion of Adequacy.
Let us begin by examining several examples of the kind of arguments an
inductive logic should explicate. Consider the following two arguments:
Example 1.. Every raven in a random sample of
3200 ravens is black. This strongly supports the hypothesis that all ravens
are black.
Example 2. 62 percent of voters in a random sample of 400
registered voters (polled on February 20, 2004) said that they favor John
Kerry over George W. Bush for President in the 2004 Presidential election.
This supports with a probability of at least .95 the hypothesis that between
57 percent and 67 percent of all registered voters favor Kerry over Bush for
President (at or around the time the poll was taken).
An argument of this kind is often called an induction by enumeration
of cases. We may represent the logical form of such arguments semi-formally as
follows:
Premise: In random sample S consisting of n
members of population B, the proportion of members that have
attribute A is r.
Therefore, with degree of support p,
Conclusion: The proportion of all members of B that have attribute
A is between r−q and r+q (i.e.,
is within margin of error q of r).
Let's lay out this argument more formally. The Premise breaks down into three
separate premises:[1]
|
Semi-formalization |
Formalization |
| Premise 1 |
The frequency (or proportion) of members with attribute A
among the members of B in S is r. |
F[A,B∩S] =
r |
| Premise 2 |
S is a random sample of B with respect to whether
or not its members have A |
Random[S,B,A] |
| Premise 3 |
Sample S has exactly n members |
Size[S] = n |
| Therefore |
(with degree of support p) |
========[p] |
| Conclusion |
The proportion of all members of B that have attribute
A is between r−q and r+q
(i.e., is within margin of error q of r) |
F[A,B] = r ±
q |
Any inductive logic that encompasses such arguments should address two
challenges. (1) It should tell us which enumerative inductive arguments should
count as good inductive arguments, rather than as inductive fallacies.
In particular, it should tell us how to determine the appropriate
degree p to which such premises inductively support
the conclusion, for a given margin of error q. (2) It should
demonstrably satisfy the CoA. That is, it should be provable (as a metatheorem)
that if a conclusion expressing the approximate proportion for an
attribute in a population is true, then it is very likely that
sufficiently numerous random samples of the population will provide true
premises for good inductive arguments that confer degrees of
support p approaching 1 for that true conclusion—where, on pain of
triviality, these sufficiently numerous samples are only a tiny
fraction of a large population. Later we will see how a probabilistic inductive
logic may meet these two challenges.
Enumerative induction is rather limited in scope. This form of induction is
only applicable to the support of claims involving simple universal conditionals
(i.e., claims of form ‘All Bs are As’) or claims about the
proportion of an attribute in a population (i.e., ‘The frequency of As
among the Bs is r’). And it applies only when the evidence for
such claims consists of instances of Bs observed to be either
As or non-As. However, many important empirical hypotheses are
not reducible to this simple form, and the evidence for hypotheses is often not
composed of simple instances. Consider, for example, the Newtonian Theory of
Mechanics:
All objects remain at rest or in uniform motion unless acted upon
by some external force. An object's acceleration (i.e., the rate at which its
motion changes from rest or uniform motion) is in the same direction as the
force exerted on it; and the rate at which the object accelerates due to a
force is equal to the the magnitude of the force divided by the object's mass.
If an object exerts a force on another object, the second object exerts an
equal amount of force on the first object, but in the opposite direction to
the force exerted by the first object.
The evidence for (and against) this theory is not gotten by examining a
randomly selected subset of objects and the forces acting upon them. Rather, the
theory is tested by calculating observable phenomena entailed by it in a wide
variety of specific situations—ranging from simple collisions between small
bodies to the trajectories of planets and comets—and then seeing whether those
phenomena really occur. This approach to testing hypotheses and theories is
ubiquitous, and should be captured by an adequate inductive logic.
Many less theoretical instances of inductive reasoning also fail to be
captured by enumerative induction. Consider the kinds of inferences members of a
jury are supposed to make based on the evidence presented at a murder trial. The
inference to probable guilt or innocence is usually based on a patchwork of
various sorts of evidence. It almost never involves consideration of a randomly
selected sequences of past situations when people like the accused committed
similar murders. Or, consider how a doctor diagnoses her patient on the basis of
his symptoms. Although the frequency of occurrence of various diseases when
similar symptoms were present may play a role, this is clearly not the whole
story. Diagnosticians commonly employ a form of hypothetical
reasoning—e.g., if the patient has a brain tumor, would that account for
all of his symptoms?; or are these symptoms more likely the result of a minor
stroke?; or is there another possible cause? The point is that a full account of
inductive logic should not be limited to enumerative induction, but should also
explicate the logic of hypothetical reasoning through which hypotheses
and theories are tested on the basis of their predictions about specific
observations. In Section 3 we will see how probabilistic inductive logic
captures such reasoning.
Probability, and the equivalent notion odds, are the oldest
and best understood ways of representing partial belief and uncertain inference.
Probability has been studied by mathematicians for over 350 years, but the
concept is certainly much older. In recent times a number of other related
representations of uncertainty have emerged. Many of these have found useful
application in computer based artificial intellegence systems that perform
inductive inferences in expert domains such as medical diagnosis. This article
will explicate the representation of inductive inferences in terms of
probability. A brief comparative description of some of the most
prominent alternative representations may be found in the following
supplementary document:
Some Prominent Approaches for Representing Uncertain Inferences.
The mathematical study of probability origniated with Blaise Pascal and
Pierre de Fermat in the mid-17th century. From that time through the
early 19th century, as the mathematical theory continued to develop,
the theory was primarily applied to the assessment of risk in games of chance
and to drawing simple statistical inferences about characteristics of large
populations — e.g., to compute appropriate life insurance premiums based on
mortality rates. In the early 19th century Pierre de Laplace made
further theoretical advances, and showed how to apply probabilistic reasoning to
a much wider range of scientific and practical problems. Since that time
probability has become an indispensable tool in the sciences, business, and many
other areas of modern life.
Throughout its development various researchers appear to have thought of
probability as a kind of logic. But the first extended treatment of probability
as an explicit part of logic was George Boole's The Laws of Thought
(1854). John Venn followed two decades later with a related logical account of
probability in The Logic of Chance (1876). Not long after that the
whole discipline of logic was transformed by new developments in deductive
logic.
In the late 19th and early 20th century Frege, followed
by Russell and Whitehead, showed how deductive logic could be represented in the
kind of rigorous formal system we now call quantificational logic or
predicate logic. For the first time logicians had a fully formal
deductive logic powerful enough to represent all valid deductive arguments in
mathematics and the sciences—a logic in which the validity of deductive
arguments depends only on the logical structure of the sentences involved. This
development spurred some logicians to attempt to apply a similar approach to
inductive reasoning. The idea was to extend the deductive entailment relation to
a notion of probabilistic entailment for cases where premises provide
less than conclusive support for conclusions. These partial entailments
are expressed in terms of conditional probabilities, probabilities of
the form P[C |
B] = r (read “the probability of C given
B is r”), where P is a probability function,
C is a conclusion sentence, B is a conjunction of premise
sentences, and r is the probabilistic degree of support that B
provides for C. Attempts to develop such a logic have varied widely in
regard to precisely how the deductive model is emulated.
Some inductive logicians have tried to follow the deductive paradigm very
closely. In deductive logic the syntactic structure of the sentences involved
completely determines whether premises logically entail a conclusion. So these
logicians attempted to specify inductive support probabilities solely in terms
of the syntactic structure of premise and conclusion sentences. In such a system
each sentence confers a syntactically specified degree of support on each of the
other sentences of the language. The inductive probabilities in such a system
are logical in the sense that they depend on syntactic structure alone.
This kind of conception was first articulated by John Maynard Keynes in his
Treatise on Probability (1921). Rudolf Carnap pursued this idea with
greater rigor in his Logical Foundations of Probability (1950) and in
several subsequent works (e.g., Carnap 1952). (For details of Carnap's approach
see the section on logical
probability in the entry on interpretations
of the probability calculus, in this Encyclopedia.)
In the inductive logics of Keynes and Carnap, Bayes's theorem, which is a
theorem of probability theory, plays a central role in expressing how evidence
comes to bear on hypotheses. (We'll examine Bayes's theorem later.) So, such
approaches might well be called Bayesian logicist inductive logics.
Other well-known Bayesian logicist attempts to develop a probabilistic inductive
logic include (Jeffreys, 1939), (Jaynes, 1968), and (Rosenkrantz, 1981).
It is now generally held that the core idea of Bayesian logicism is fatally
flawed—that syntactic logical structure cannot be the sole determiner of the
degree to which premises inductively support conclusions. A crucial facet of the
problem faced by Bayesian logicism involves how the logic is supposed to apply
to scientific contexts where the conclusion sentence is some hypothesis or
theory, and the premises are evidence claims. The difficulty is that in
any probabilistic logic that satisfies the usual axioms for
probabilities, the inductive support for a hypothesis must depend in part on its
prior probability. This prior probability represents how
plausible the hypothesis is supposed to be on its own, before the evidence is
brought to bear. A Bayesian logicist must tell us how to assign values to these
pre-evidential prior plausibilities for each hypothesis or theory under
consideration, and must do so in a way that relies only on their syntactic
logical structure, or on some measure of their syntactic simplicity. There are
severe technical problems with getting this idea to work. Moreover, various
counter-examples seem to show that such an approach must assign intuitively
quite unreasonable prior probabilities to many hypotheses. Thus, it appears that
logical structure alone cannot distinguish good inductive inferences from bad
ones. (We will describe this problem in more detail, and provide such a
counterexample, in Section 3, after we spell out the details of how
probabilistic logics represent the confirmation of hypotheses.)
At about the time the Bayesian logicist idea was developing, an alternative
conception of probabilistic inductive reasoning was also emerging. This approach
is now generally referred to as the Bayesian subjectivist or
personalist approach to inductive reasoning (see, e.g., Ramsey, 1926;
De Finetti, 1937; Savage 1954; Edwards, Lindman, Savage, 1963; Jeffrey, 1983,
1992; Howson, Urbach, 1993; Joyce 1999). It treats inductive probability as part
of a larger normative theory of belief and action known as Bayesian decision
theory. The principle idea is that the strength of an agent's desires for
various possible outcomes should combine with her belief-strengths regarding
claims about the world to produce optimally rational decisions. Bayesian
subjectivists provide a logic that captures this idea, and they attempt to
justify this logic by showing that in principle it leads to optimal decisions
about which of various risky alternatives should be pursued. On the Bayesian
subjectivist or personalist account of inductive probability, inductive
probability functions represent the subjective (or personal) belief-strengths of
ideally rational agents, the kind of belief strengths that figure into rational
decision making. (See the section on subjective
probability in the entry on interpretations
of the probability calculus, in this Encyclopedia.)
Elements of the logicist conception of inductive logic live on today as part
of the general approach called Bayesian inductive logic. However, among
philosophers and statisticians the term ‘Bayesian’ is now most closely
associated with the subjectivist or personalist account of belief and decision.
And the term ‘Bayesian inductive logic’ has come to carry the connotation of a
logic that involves purely subjective probabilities. This current usage is
misleading since in inductive logic the Bayesian/non-Bayesian distinction should
really hang on whether the logic gives Bayes's theorem a prominent role, or
whether the logic largely eschews the use of Bayes's theorem in inductive
inferences, as does the classical approach to statistical inference.
Indeed, any inductive logic that draws on the usual axioms of probability theory
to express the probabilistic support of hypotheses by evidence almost has to be
a Bayesian inductive logic in this broader sense.
In this article the probabilistic inductive logic we will examine is
a Bayesian inductive logic in the broader sense. This logic will not
presuppose the subjectivist Bayesian theory of belief and decision, and
will avoid the objectionable features of Bayesian logicism. We will see that
there are good reasons to distinguish inductive probabilities from both
Bayesian degree-of-belief probabilities and from purely
logical probabilities. So, the probabilistic logic articulated in his
article will be presented in an autonomous way, though it may be fitted into a
Bayesian subjectivist or Bayesian logicist program, if one desires to do so.
All logics derive from the meanings of terms in sentences. What we now
recognize as formal deductive logic rests on the meanings (i.e., the
truth-functional properties) of the standard logical terms. These terms, and the
symbols we will employ to represent them, are as follows: ‘not’, ‘~’; ‘and’,
‘·’; ‘or’, ‘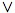 ’; truth-functional
‘if-then’, ‘⊃’; ‘if and only if’, ‘≡’; the quantifiers ‘all’, ‘∀’, and ‘some’,
‘∃’; and the identity relation, ‘=’. The meanings of all other terms (i.e.,
names, and predicate and relational expressions) are permitted to “float free”.
That is, the logic doesn't depend on their meanings or the truth-values of
sentences containing them, but only supposes them to be meaningful and that
sentences containing them have truth-values. Deductive logic only tells us that
the logical structures of some sentences — i.e., the syntactic arrangements of
their logical terms — preclude them from being jointly true of any single
possible state of affairs. This is the notion of logical inconsistency.
The notion of logical entailment is interdefinable with it. A
collection of premise sentences logically entails a conclusion sentence
just when the negation of the conclusion is logically inconsistent with
those premises.
’; truth-functional
‘if-then’, ‘⊃’; ‘if and only if’, ‘≡’; the quantifiers ‘all’, ‘∀’, and ‘some’,
‘∃’; and the identity relation, ‘=’. The meanings of all other terms (i.e.,
names, and predicate and relational expressions) are permitted to “float free”.
That is, the logic doesn't depend on their meanings or the truth-values of
sentences containing them, but only supposes them to be meaningful and that
sentences containing them have truth-values. Deductive logic only tells us that
the logical structures of some sentences — i.e., the syntactic arrangements of
their logical terms — preclude them from being jointly true of any single
possible state of affairs. This is the notion of logical inconsistency.
The notion of logical entailment is interdefinable with it. A
collection of premise sentences logically entails a conclusion sentence
just when the negation of the conclusion is logically inconsistent with
those premises.
An inductive logic must, it seems, deviate from this paradigm in several
significant ways. For one thing, logical entailment is an absolute,
all-or-nothing relationship between sentences, whereas inductive support comes
in degrees of strength. For another, although the notion of inductive
support is analogous to the deductive notion of logical
entailment, and is arguably an extension of it, there seems to be no
inductive logic extension of the notion of logical inconsistency—at
least none that is inter-definable with inductive support in the way
that logical inconsistency is inter-definable with logical
entailment. That is, B logically entails A just when
(B·~A) is logically inconsistent. However, it turns
out that when the unconditional probability of (B·~A) is very
nearly 0 (i.e., when (B·~A) is “nearly inconsistent”), the
degree to which B inductively supports A, P[A | B], may
range anywhere from nearly 0 to very near 1.
Another notable difference is that when B logically entails
A, adding a premise C cannot undermine the entailment—i.e.,
(C·B) must entail A as well. This property of
logical entailment is called monotonicity. But inductive
support is nonmonotonic. Adding a new premise C to
B may substantially raise the degree of support for A, or
substantially lower it, or may leave it completely unchanged—i.e., P[A |
C·B] may have a value much larger than P[A | B], or a
much smaller value, or it may have the same, or nearly the same value.
In a formal treatment of probabilistic inductive logic, inductive support is
represented by conditional probability functions defined on sentences of a
formal language L. These probability functions are constrained by
certain rules or axioms regarding the role played by the logical terms (i.e.,
‘not’, ‘and’, ‘or’, etc., the quantifiers ‘all’ and ‘some’, and the identity
relation). The axioms apply without regard for what the other terms of the
language may mean. In essence the axioms specify a family of possible
support functions, {Pβ, Pγ, … ,
Pδ, …} for a given language L. Although each
support function satisfies these same axioms, the further issue of which among
them provides an appropriate measure inductive support is not settled
by the axioms alone. That may depend on additional factors, such as the meanings
of the non-logical terms in the language.
A good way to specify the rules or axiom of the logic of inductive support
functions is as follows. Let L be a language for predicate logic with
identity, and let ‘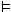 ’ be
the standard logical entailment relation.
’ be
the standard logical entailment relation.
A support function is a function Pα from pairs
of sentences of L to real numbers between 0 and 1 that satisfies the
following rules or axioms:
- Pα[D | E] < 1 for some
sentences D and E.
For all sentence A, B, C, and D,
- If BA, then
Pα[A | B] =1;
- If (B≡C), then
Pα[A | B] =
Pα[A | C];
- If C
~(B·A), then either Pα[(A
B) | C] =
Pα[A | C] +
Pα[B | C] or
Pα[D | C] = 1;
- Pα[(A·B) | C] =
Pα[A | (B·C)] ·
Pα[B | C].
This axiomatization takes conditional probability as basic, as seems
appropriate for support functions. These functions agree with the usual
unconditional probability functions when the latter are defined—just let Pα[A] = Pα[A | (D ~D)]. However, these
axioms permit conditional probabilities Pα[A |
C] to remain defined even when condition statement C
has probability 0 (i.e., even when Pα[C | (D~D)]).
Notice that conditional probability functions apply only to pairs of
sentences, a premise sentence and a conclusion sentence. So in probabilistic
inductive logic we represent finite collections of premises by conjoining them
into a single sentence. Rather than say, ‘A is supported to degree
r by the premises {B1,
B2,…,Bn}’, we say ‘A is
supported to degree r by the premise
(B1·B2·…·Bn)’, and
write this as ‘P[A |
(B1·B2·…·Bn)]
= r’.
Let us briefly consider each axiom, 1-5, to see how plausible it is as a
constraint on a quantitative measure of inductive support, and how it extends
the notion of deductive entailment. First, notice that adopting an inductive
support scale between 0 and 1 is merely a convenience. This scale is usual for
probabilities; but any other scale might do as well.
Rule (1) is a non-triviality requirement. It says that some sentences must be
supported by others to degree less than 1. We might instead have required that
Pα[(A·~A) |
(A~A)]
< 1; but this turns out to be derivable from Rule (1) together with the other
rules.
Each degree-of-support function Pα on L measures
support strength with numerical values between 0 and 1, with maximal
support at 1. Deductive entailment can be viewed as a special case of
maximal inductive support. So, when B logically entail
A, B supports A to the maximum extent. This is just
what Rule (2) asserts. It comports with the idea that an inductive support
function is a kind of generalization of the deductive entailment relation.
Rule (3) is equally obvious. It says that whenever B is logically
equivalent to C, as premises each must provide precisely the same
amount of support to every conclusion.
Rule (4) says that inductive support “adds up” in a plausible way. When
C logically entails the incompatibility of A and B,
the support C provides each separately must sum to the support it
provides for their disjunction. The only exception is in cases where C
acts like a contradiction and supports all sentences to degree 1.
To understand what Rule (5) says, think of a support function
Pα as describing a measure on possible worlds or possible
states of affairs. ‘Pα[C |
D] = r’ says that the proportion of worlds in which
C is true among those where D is true is r. Rule (5)
then says the following: if A is true in fraction r of worlds
where B and C are true together, and if B (together
with C) is true in proportion q of all the C-worlds,
then A and B (and C) should be true together in
fraction r of that proportion q of B (and C)
worlds among the C-worlds.[2]
From these five rules or axioms, all of the usual theorems of probability
theory are easily derived. For example, logically equivalent sentences are
always supported to the same degree: if C(B≡A), then Pα[A |
C] = Pα[B |
C]. The following generalization of the Addition Rule (4) holds:
Pα[(AB) | C] =
Pα[A | C] +
Pα[B | C] −
Pα[(A·B) | C].
It also follows that if {B1,…, Bn,…}
is any countable set of sentences such that for each pair Bi
and Bj, C
~(Bi·Bj) (i.e., the members of
the set are mutually exclusive, given C), then limn
Pα[(B1B2 …Bn) | C]
= ∑i Pα[Bi |
C], unless Pα[D |
C] = 1 for every sentence D.[3]
In the context of inductive logic it makes good sense to supplement the above
rules with two additional rules. One is this:
- If A is an axiom of set theory or any other piece of pure
mathematics employed by the sciences, or if A is analytically truth
(given the meanings of terms in L), then, for all C, Pα[A |
C] = 1.
The idea is that inductive logic is about evidential support for contingent
claims. Nothing can count as empirical evidence against non-contingent truths.
They should be “maximally supported” by all claims.
One important respect in which inductive logic should follow the deductive
paradigm is in not presupposing the truth-values of contingent sentences. No
inductive support function Pα should permit a
tautological premise to assign degree of support 1 to a contingent claim—i.e.,
Pα[C | B
~B] should
always be less than 1 when C is contingent. For, the whole idea of
inductive logic is to provide a measure of the extent to which contingent
premise sentences indicate the likely truth-values of contingent conclusion
sentences. And this idea won't work properly if the truth-values of some
contingent sentences are presupposed. Such presuppositions would make inductive
logic enthymematic. It may hide significant premises in inductive support
relationships.
However, it is common practice for probabilistic logicians to sweep
provisionally accepted contingent claims under the rug by assigning them
probability 1. This saves the trouble of repeatedly writing a given contingent
sentence B as a premise, since Pγ[A |
B·C] will just equal Pγ[A |
C] whenever Pγ[B |
C] = 1. Although this device is useful, such probability
functions should be considered mere abbreviations of proper, logically explicit,
non-enthymematic, inductive support functions. Thus, properly speaking, an
inductive support function Pα should not assign probability
1 to a sentence relative to all possible premises unless that sentence
is either (i) logically true, or (ii) an axiom of set theory or some other piece
of pure mathematics employed by the sciences, or (iii) unless according to the
interpretation of the language that Pα presupposes, the
sentence is analytic, and so outside the realm of evidential support.
Thus, we adopt the following version of the so-called “axiom of regularity”.
- If, for all C, Pα[A | C] =
1, then A is a logical truth or an axiom of set theory or some other
piece of pure mathematics employed by the sciences, or is analytically true
(according to the meanings of the terms of L as represented in
Pα).
This is more a convention than an axiom. Taken together with (6) it tells us
that a support function Pα counts as non-contingently true
just those sentences that it assigns probability 1 on every premise.
Bayesian logicists such as Keynes and Carnap thought that inductive logic
might be made to depend solely on the logical form of sentences, just like
deductive logic. The idea was, effectively, to supplement axioms 1-7 with
additional axioms that depend only on the logical structures of sentences, and
to do so with enough such axioms to reduce the number of possible support
functions to a single unique function. It is now widely agreed that this project
cannot be carried out in a plausible way. Perhaps there are additional rules
that should be added to 1-7. But it is doubtful such rules can suffice to
specify a single, uniquely qualified support function based only on logical
structure. We will show why in Section 3, after seeing how inductive
probabilities capture the relationship between hypotheses and evidence.
Axioms 1-7 for conditional probability functions merely place formal
constraints on what may properly count as a degree of support function.
Each function Pα satisfying these rules may be viewed as a
possible way of applying the notion of inductive support to a language
L that respects the meanings of the logical terms, much as each
possible truth-value assignment for a language represents a possible
way of assigning truth-values to its sentences in a way that respects the
semantic rules expressing the meanings of the logical terms. The issue of which
of the possible truth-value assignments to a language represents the
actual truth or falsehood of its sentences depends on more than this—it
depends on the meanings of the non-logical terms and on the state of the actual
world. Similarly, the degree to which some sentences actually support
others in a fully meaningful language must rely on something more than merely
satisfying the axioms for support functions. It must, at least, rely on what the
sentences of the language mean, and perhaps on much more besides. But, what
more? Various “interpretations of probability”, which offer accounts of how
support functions are to be understood, may help by filling out our conception
of what inductive support is really about. There are two prominent
views.
One reading is to take each Pα as a measure on possible
worlds, or possible states of affairs. The idea is that, given a fully
meaningful language (and, perhaps relative to the inferential inclinations of a
particular agent, α) ‘Pα[A |
B] = r’ says that among the worlds in which B
is true, A is true in proportion r of them. There will
generally not be a single privileged way to define such a measure on possible
worlds. Rather, it may be that each of a number of functions
Pα, Pβ, Pγ, …, etc.,
satisfying the constraints imposed by axioms 1-7 can represent a viable measure
of the inferential import of propositions expressed by sentences of the
language. This idea needs more fleshing out, of course. The next section will
give some indication of how that might go.
Subjectivist Bayesians offer an alternative reading of the support
functions. First, they usually take unconditional probability as basic, and they
take conditional probabilities as defined in terms of them: the conditional
probability ‘Pα[A
| B]’ is defined as a ratio of unconditional probabilities,
Pα[A·B]/
Pα[B].
Subjectivist Bayesians take each unconditional probability function
Pα to represent the belief-strengths or confidence-strengths
of an ideally rational agent, α. On this understanding ‘Pα[A]
=r’ says, “the strength of α's belief (or confidence) that A
is truth is r.” Subjectivist Bayesians usually tie such belief
strengths to what the agent would be willing to bet on A turning out to
be true. Roughly, the idea is this. Suppose that an ideally rational agent α
would be willing to accept a wager that would yield (no less than) $u
if A turns out to be true and would lose him $1 if A turns out
to be false. Then, under reasonable assumptions about how much he desires money,
it can be shown that his belief strength that A is true should be Pα[A] =
1/(u+1). And it can further be shown that any function
Pα that expresses such betting-related belief-strengths on
all statements in agent α's language must satisfy axioms for unconditional
probabilities analogous to axioms 1-5. [4] Moreover, it can be shown that any function
Pβ that satisfies these axioms is a possible rational belief
function for some ideally rational agent β. These relationships between
belief-strengths and the desirability of outcomes (e.g., gaining money or goods
on bets) are at the core of subjectivist Bayesian decision theory.
Subjectivist Bayesians usually take inductive probability to
just be this notion of probabilistic belief-strength.
Undoubtedly real agents do believe some claims more strongly than others.
And, arguably, the belief strengths of real agents can be measured on a
probabilistic scale between 0 and 1, at least approximately. And clearly the
inductive support of evidence for hypotheses should influence the strength of an
agent's belief in those hypotheses. However, there is good reason for caution
about viewing inductive support functions as Bayesian belief-strength
functions, as we will see a bit later. So, perhaps an agent's support function
is not simply identical to his belief function, and perhaps the
relationship between inductive support and belief-strength is
somewhat more complicated.
In any case, some account of what support functions are supposed to represent
is clearly needed. The belief function account and the possible worlds account
are two attempts to provide this. Let us put this interpretative issue aside for
now. One may be able to get a better handle on what inductive support functions
really are after one sees how the inductive logic that draws on them is
supposed to work.
One of the most important applications of a formal inductive logic is to the
confirmation or refutation of scientific hypotheses. The logic should explicate
the notion of evidential support for all sorts of hypotheses, ranging from
simple diagnostic claims (e.g., “the patient is infected with the HIV”) to
scientific theories about the fundamental nature of the world, like quantum
mechanics or the theory of relativity. We'll now look into how support functions
represent the logic of confirmation.
To begin with, consider some exhaustive set {h1,
h2,…} of mutually incompatible hypotheses or theories about
some subject matter. The set of alternatives may be very simple, e.g., {“the
patient has HIV”, “the patient is free of HIV”}. Or, when the physician is
trying to determine which among a range of diseases is causing the patients
symptoms, the alternative hypotheses may consist of a long list of possible
diseases. For the cosmologist the alternatives may be a list of several
alternative gravitational theories, or several versions of the “same theory“.
Where inductive logic is concerned, even a slightly different version of a given
theory will count as a distinct theory if it differs from the original in
empirical import. (This should not be confused with the converse claim, which is
the positivistic assertion that theories with the same empirical content are
really the same theory. Inductive logic doesn't require you to buy that!)
In general there may be finitely or infinitely many such alternatives under
consideration. They may all be considered at once, or they may be constructed
and compared over a long historical period. One may even think of the set of
alternative hypotheses as consisting of all logically possible alternatives
expressible in a given language about a given subject matter—e.g., all possible
theories of the origin and evolution of the universe expressible in English and
mathematics. Although testing every possible alternative may pose practical
challenges, it turns out that the logic works much the same way in the logically
ideal case as it does in realistic cases.
If the set of alternative hypotheses is finite, it may contain a
catch-all hypothesis hK that says that
none of the other hypotheses are true (e.g., “none of the other known diseases
is present”). When only some number u of explicit alternative hypotheses is
under consideration, hK is just the sentence
(~h1·…·~hu).
Evidence for scientific hypotheses consists of the results of specific
experiments or observations. For a given experiment or observation, let
‘c’ represent a description of the relevant conditions under
which it is performed, and let ‘e’ represent a description of the
result, the evidential outcome of condition c.
Scientific hypotheses often require the the mediation of background knowledge
and auxiliary hypotheses to help them express claims about evidence. Let
‘b’ represent all backgroud and auxilliaries not at issue in the
assessment of the hypotheses hi, but that mediate
their implications about evidence. In cases where a hypothesis is deductively
related to evidence, either
hi·b·c e or
hi·b·c ~e.
For example, hi might be Newtonian Theory of
Gravitation. A test of the theory might involve a condition statement c
describing the results of some earlier measurements of Jupiter's position, and
describing the means by which the next position measurement will be made; the
outcome description e states the result of this additional position
measurement; and the background information (or auxiliary hypotheses) b
might state some already well confirmed theory about the workings and accuracy
of the devices used to make the position measurements. If outcome e can
be calculated from the theory hi together with b
and c, we have hi·b·c
e
(hi·b·c logically
entails e). Thus, if (c·e) occurs, this may be
considered good evidence for hi, given b,
as the hypothetico-deductive account of confirmation maintains. On the
other hand, if from hi·b·c we
calculate some outcome incompatible with e, then
hi·b·c ~e. In that case from deductive
logic alone we get that b·c·e ~hi, and
hi is said to be falsified by
b·c·e. (Duhem (1906) and Quine (1953) are generally
credited with alerting inductive logicians to the importance of auxilliary
hypotheses. They point out that scientific hypotheses often make little contact
with evidence claims on their own. So, often the evidence can only falsify
hypotheses relative to the background or auxilliary hypotheses that tie them to
that evidence.)
In a probabilistic inductive logic the degree to which evidence
c·e supports a hypothesis hi
relative to background b is represented by the posterior
probability of hi, Pα[hi
|
b·cn·en].
It turns out that the posterior probability of a hypothesis depends on
just two kinds of factors: (1) its prior probability, Pα[hi
| b], together with the prior probabilities of its competitors,
Pα[hj
| b], etc.; and (2) the likelihood of evidential
outcomes e according to hi, give that
b and c are true, P[e |
hi·b·c], together with the
likelihoods of outcomes according to its competitors, P[e |
hj·b·c], etc. In this
section we will first examine each of these two kinds of factors in some detail,
and then see precisely how the values of posterior probabilities depend on
them.
In probabilistic inductive logic the likelihoods carry the empirical
import of hypotheses. A likelihood is a support function probability of
form P[e |
hi·b·c]. It expresses how
likely it is that outcome e will occur according hypothesis
hi.[5] If a hypothesis together with auxiliaries and
observation conditions deductively entails an evidence claim, the axioms of
probability make the corresponding likelihood objective in the sense that every
support function must agree on its values: i.e., P[e |
hi·b·c] = 1 if
hi·b·c e; P[e |
hi·b·c] = 0 if
hi·b·c ~e. However, in many cases the
hypothesis hi will not be deductively related to
the evidence, but will only imply it probabilistically. There are (at least) two
ways this might happen. Either hi may itself be an
explicitly probabilistic or statistical hypothesis, or it may be that an
auxiliary statistical hypothesis, as part of background b, connects
hi to the evidence. Let's briefly consider examples
of each.
A blood test for HIV has a known false-positive rate and a known
true-positive rate. Suppose the false positive rate is .05 — i.e., the test
incorrectly shows the blood sample to be positive for HIV in 5% of all cases
where no HIV is present. And suppose the true-positive rate is .99—i.e., the
test correctly shows the blood sample to be positive for HIV in 99% all cases
where HIV really is present.When a particular patient's blood is tested, the
hypotheses under consideration are ‘the patient is infected with HIV’,
h, and ‘the patient is not infected with HIV’, ~h. In this
context the known test characteristics function as background information,
b. The experimental condition c merely states that this
patient was subjected to a blood test for HIV, which was processed by the lab in
the usual way. Let us suppose that the outcome e states that the result
is positive for HIV. The relevant likelihoods, then, are P[e |
h·b·c] = .99 and P[e |
~h·b·c] = .05.
In this example the values of the likelihoods are entirely due to the
statistical characteristics of the accuracy of the test, which is carried by the
background information b. The hypothesis h being tested is not
itself statistical.
This kind of situation may, of course, arise for much more complex
hypotheses. The hypothesis of interest may be some deterministic physical
theory, say Newtonian Gravitation Theory. Some of the experiments that test this
theory relay on somewhat imprecise measurements that have known statistical
error characteristics, which are expressed as part of the background or
auxiliary hypotheses b. For example, the auxiliary b may
describe the error characteristics of a device that measures the torque imparted
to a quartz fiber, used to assess the strength of the gravitational force
between test masses. In that case b may say that for this kind of
device measurement errors are normally distributed about whatever value a given
gravitational theory predicts, with some specified standard deviation that is
characteristic of the device. This results in specific values
ri for the likelihoods, P[e |
hi·b·c] =
ri, for each of the various alternative
gravitational theories hi being tested.
On the other hand, the hypotheses being tested may themselves be statistical
in nature. One of the simplest examples of statistical hypotheses and their role
in likelihoods are hypotheses about the chance characteristic of coin-tossing.
Let h[r] be a hypothesis that says a specific coin
has a propensity r (e.g., 1/2) for coming up heads on normal tosses,
and that such tosses are probabilistically independent of one another. Let
c state that the coin is tossed n times in the normal way; and let
e say that on these tosses the coin comes up heads m times. In
cases like this the value of the likelihood of the outcome e on
hypothesis h for condition c is well-known: P[e |
h[r]·b·c] = [n!/(m!(n−m)!)]
rm
(1−r)n−m.
There are, of course, more complex cases of likelihoods involving statistical
hypotheses. Consider, for example, the hypothesis that plutonium 233 nuclei have
a half-life of 20 minutes—i.e., the propensity for a Pu-233 nucleus to decay
within a 20 minute period is 1/2. This hypothesis, h, together with
background b about decay products and the efficiency of the equipment
used to detect them (which may itself be an auxiliary statistical hypothesis),
yields precisely calculable values for likelihoods
P[ek | h·b·c]
of possible outcomes of the experimental arrangement.
Likelihoods that arise from explicit statistical claims — either within the
hypotheses being tested, or from explicit statistical background claims that tie
the hypotheses to the evidence — are often called direct inference
likelihoods. Such likelihoods are completely objective. So it seems
reasonable to suppose that all support functions should agree on their values,
just as all support functions agree on likelihoods when evidence is logically
entailed. Direct inference likelihoods are logical in an extended,
non-deductive sense. Indeed, some logicians have attempted to spell out the
logic of direct inferences in terms of the logical form of the
sentences involved.[6] But regardless of whether that project succeeds, it
seems reasonable to take likelihoods of this sort to have highly objective or
intersubjectively agreed values.
Not all likelihoods of interest in confirmational contexts are warranted
deductively or by explicitly stated statistical claims. Nevertheless, the
likelihoods that relate hypotheses to evidence in scientific contexts should
often have objective or intersubjectively agreed values. So, although a variety
of different support functions Pα, Pβ
,…, Pγ, etc., may be needed to represent the differing
“inductive proclivities” of the various members of a scientific community, all
should agree, at least approximately, on the values of the likelihoods. For,
likelihoods represent the empirical content of a hypothesis, what the hypothesis
(together with background b) probabilistically implies about
the evidence. Thus, the empirical objectivity of a science relies on a high
degree of objectivity or intersubjective agreement among scientists on the
numerical values of likelihoods.
To see the point more vividly, imagine what a science would be like if
scientists disagreed widely about the values of likelihoods. Each practitioner
interprets a theory to say quite different things how likely it is that
various possible evidence statements will turn out to be true. Whereas scientist
α takes theory h1 to probabilistically imply that event
e is highly likely, his colleague β understands the empirical import of
h1 to say that e is very unlikely. And, conversely,
α takes competing theory h2 to probabilistically imply that
e is quite unlikely, whereas β reads h2 to say that
e is very likely. So, for α the evidence outcome e supplies
strong support for h1 over h2, because
Pα[e |
h1·b·cn]
>> Pα[e |
h2·b·c]. But his colleague β takes
outcome e to show just the opposite — that h2 is
strongly supported over h1 — because Pβ[e |
h1·b·c] << Pβ[e |
h2·b·c]. If this kind of thing were
to occur often or for significant evidence claims in a scientific domain, it
would make a shambles of the empirical objectivity of that science. It would
completely undermine the empirical testability of its hypotheses and theories.
Under such circumstances, although each scientist employs the same
theoretical sentences to express a given theory h, each
understands the empirical import of these sentences so differently that
h as understood by α is an empirically different theory than h
as understood by β. Thus, the empirical objectivity of the sciences requires
that experts should be in close agreement about the values of the
likelihoods.[7]
For now we will suppose that the likelihoods have objective or
intersubjectively agreed values, common to all agents in a scientific community.
Let us mark this agreement by dropping the subscript ‘α’, ‘β’, etc., from
expressions that represent likelihoods. One might worry that this supposition is
overly strong. There are many legitimate scientific contexts where, although
scientists should have enough of a common understanding of the empirical import
of hypotheses to assign quite similar values to likelihoods,
precise agreement on the numerical values is unrealistic. This point is
well taken. Later we will see how to relax the supposition that likelihood
values agree precisely. But for now, the main ideas behind probabilistic
inductive logic will be more easily explained if we focus on those contexts were
objective or intersubjectively agreed likelihoods are available. Towards the end
of this article we will see that much the same logic continues to apply in
contexts where the values of likelihoods may be somewhat vague, or where members
of the scientiific community disagree to some extent about their values.
An adequate treatment of the likelihoods calls for the introduction of one
additional notational device. Scientific hypotheses are generally tested by a
sequence of experiments or observations conducted over a period of time. To
explicitly represent the accumulation of evidence, let the series of sentences
c1, c2, …,
cn, describe the conditions under which a sequence
of experiments or observations are conducted. And let the corresponding outcomes
of these observations be represented by sentences e1,
e2,…,en. We will abbreviate the
conjunction of the first n descriptions of experimental or observation
conditions as ‘cn’, and abbreviate the conjunction
of descriptions of their outcomes as ‘en’. Then,
for a stream of n observations or experiments and their outcomes, the
likelihoods take form P[en |
hi·b·cn]
= r, for appropriate r between 0 and 1. In many cases in the
sciences the likelihood of the evidence stream is equal to the product of the
likelihoods of the individual outcomes: P[en |
hi·b·cn]
= P[e1 |
hi·b·c1] ·…·
P[en |
hi·b·cn].
When this holds, the individual bits of evidence are said to be
probabilistically independent on the hypothesis. However, such
independence may not always hold.
In probabilistic inductive logic the evaluation of a hypothesis on evidence
is represented by its posterior probability, Pα[hi
|
b·cn·en].
The posterior probability represents the net plausibility of the hypothesis
resulting from the combination of the evidence together with any relevant
non-evidential plausibility considerations. The likelihoods are the means
through which evidence contributes to posterior probabilities. But another
factor, the prior probability of the hypothesis (on background
b), Pα[hi
| b], also makes a contribution. It represents the weight of all
non-evidential plausibility considerations on which posterior plausibilities may
depend. It turns out that posterior probabilities depend only on the
values of (ratios of) likelihoods and on the values of (ratios of)
prior probabilities.
To understand the role of prior probabilities, consider the HIV test
example described in the previous section. What the physician and patient want
to know is the value of the posterior probability Pα[h |
b·c·e] that the patient has HIV, h,
given the evidence of the positive test, c·e, and given the
error rates of the test, described by b. The value of this posterior
probability depends on the likelihood (due to the error rates) of this patient
obtaining a true-positive result, P[e |
h·b·c] = .99, and of obtaining a false
positive result, P[e |
~h·b·c] = .05. In addition, the value of the
of the posterior probability depends on how plausible it is that the patient has
HIV before the test results are taken into account, Pα[h |
b]. In the context of medical diagnosis this prior probability
is sometimes called the base rate. It is the plausibility that the
patient may have contracted HIV based on his risk group (i.e., whether he is an
IV drug user, has unprotected sex with multiple partners, etc.). Such
information may be explicitly stated in the background, b. To see its
importance, consider the following numerical results (which may be calculated
using the formula called as Bayes's Theorem, presented in the next section). If
the base rate for the patient's risk group is relatively high, say Pα[h |
b] = .10, then the positive test result yields a probability for
his having HIV of Pα[h |
b·c·e] = .69. However, if the patient is in a
very low risk group, Pα[h |
b] = .001, then a positive test only raises the plausibility of
HIV infection to Pα[h |
b·c·e] = .02. This posterior probability is
much higher than the prior probability of .001, but should not worry the patient
too much. This positive test result is more likely due to the false-positive
rate of the test than to the presence of HIV. (This sort of test, with such a
large false-positive rate, .05, is best used as a screening test; a positive
result should lead to a second, more rigorous, more expensive test.)
In the evidential evaluation of scientific theories, prior probabilities
often represent assessments by agents of non-evidential, conceptually motivated
plausibility weightings among hypotheses. However, because such
plausibility assessments tend to vary among agents, critics often brand them as
merely subjective, and take their role in probabilistic induction to be
highly problematic. Bayesian inductivists counter that such assessments often
play an important role in the sciences, especially when there is insufficient
evidence to distinguish among some of the alternative hypotheses. And, they
argue, the epithet merely subjective is unwarranted. Such plausibility
assessments are often backed by extensive arguments that may draw on forceful
conceptual considerations.
Consider, for example, the kind of plausibility arguments that have been
brought to bear on the various interpretations of quantum theory (e.g., those
related to the measurement problem). These arguments go to the heart of
conceptual issues that were central to the development of the theory. Indeed,
many of these issues were first raised by the scientists who made the greatest
contributions to the theory's development, in the attempt to get a conceptual
hold on the theory and its implications. Although disagreements remain, such
arguments seem to play a legitimate role in the assessment of alternative views
when distinguishing evidence has yet to be found.
More generally, scientists often bring plausibility arguments to bear in
assessing their views. Although such arguments are seldom decisive, they may
bring the scientific community into widely shared agreement, especially
regarding the implausibility of some logically possible alternatives.
This seems to be the primary epistemic role of the thought experiment. It is
arguably a virtue of probabilistic induction that it provides a place for such
assessments to figure into the full evaluation of hypotheses. Although prior
probabilities may be subjective in the sense that agents may disagree on the
relative strengths of plausibility arguments—and so disagree on the
plausibilities of various hypotheses—priors are far from being mere
subjective whims. Moreover, probabilistic induction shows how, when
sufficient empirical evidence becomes available, such plausibility assessments
are “washed out” or overridden by the evidence. We'll see how this works in
Sections 4 and 5.
Bayesian logicists like Keynes and Carnap maintained that posterior
probabilities of hypotheses should be determined by logical form alone. The idea
was that the likelihoods might reasonably be specified in terms of logical form;
so if logical form might be made to determine the values of prior probabilities
as well, then inductive logic would be fully “formal” in the same way that
deductive logic is formal. Keynes and Carnap tried to implement this idea
through syntactic versions of the principle of indifference — the idea that
syntactically similar hypotheses should be assigned the same prior probability
values. Carnap showed how to carry out this project in detail, but only for
extremely simple formal languages. Most logicians now take the project to have
failed because of a fatal flaw with the whole idea that reasonable prior
probabilities can be made to depend on logical form alone. Semantic content
should matter. Goodmanian grue-predicates provide one way to illustrate the
point.[8]
We will return to the discussion of prior probabilities in a bit. But it is
now time to see how the likelihoods combine with prior probabilities to yield
posterior probabilities for hypotheses.
Any probabilistic inductive logic that draws on the usual axioms of
probability theory to represent how evidence supports hypotheses must be a
Bayesian inductive logic in the broad sense. For, Bayes's Theorem is
just a simple theorem of probability theory. Its importance is due to the
relationship it expresses between hypotheses and evidence. The theorem shows how
evidence, through the likelihoods, combines with prior plausibility assessments
to produce posterior plausibility values for hypotheses.
Let's now examine several forms of Bayes's Theorem, each derivable from
axioms 1-5. The simplest is this:
Bayes's Theorem: Simple Form
| (8) |
Pα[hi |
b·cn·en] |
= |
P[en |
hi·b·cn]
· Pα[hi | b]
——————————
Pα[en |
b·cn] |
· |
Pα[cn |
hi·b]
—————
Pα[cn |
b] |
|
|
|
|
|
|
|
|
|
|
= |
P[en |
hi·b·cn]
· Pα[hi | b]
—————————
Pα[en
| b·cn] |
|
if
Pα[cn |
hi·b] =
Pα[cn |
b]. |
This equation expresses the posterior probability of
hi, Pα[hi
|
b·cn·en],
in terms of the likelihood of the evidence on the hypothesis (together
with background and observation conditions), P[en |
hi·b·cn],
the prior probability of the hypothesis (given background conditions),
Pα[hi
| b], and the simple probability of the evidence (given
background and observation conditions), Pα[en
| b·cn]. This latter probability is
sometimes called the expectedness of the evidence.
This version of Bayes's Theorem also includes a term, (Pα[cn
| hi·b] /
Pα[cn | b]),
that represents the ratio of the likelihood of the experimental
conditions on the hypothesis and background to the “likelihood” of the
experimental conditions on the background alone. Bayes's Theorem is usually
expressed in a way that suppresses this factor by building
cn into the background b. However, if
cn is built into b, then technically
b must change as new evidence is accumulated. It is better to make the
factor explicit, and see how to deal with it logically. Arguably the term (Pα[cn
| hi·b] /
Pα[cn | b])
should be 1, or near 1, since the truth of the hypothesis at issue should not
significantly affect how likely it is that the experimental conditions are
satisfied. If various alternative hypotheses assign significantly different
likelihoods to the experimental conditions, then such conditions should more
properly be included in the evidential outcomes
en.
Both the prior probability of the hypothesis and the
expectedness tend to be “subjective”. That is, various agents from the
same scientific community may legitimately disagree on what values these factors
should take. Bayesian logicians usually accept the subjectivity of the prior
probabilities of hypotheses, but they find the subjectivity of the
expectedness more troubling. However, this problem is easily
finessed.
The subjective expectedness of the evidence may be circumvented by
considering a ratio form of Bayes's Theorem, a form that compares hypotheses one
pair at a time:
Bayes's Theorem: Ratio Form
| (9) |
Pα[hj |
b·cn·en]
——————
Pα[hi |
b·cn·en] |
= |
P[en |
hj·b·cn]
—————
P[en |
hi·b·cn] |
· |
Pα[hj |
b]
———
Pα[hi |
b] |
· |
Pα[cn |
hj·b]
————
Pα[cn |
hi·b] |
|
|
|
|
|
|
|
|
|
|
= |
P[en |
hj·b·cn]
—————
P[en |
hi·b·cn] |
· |
Pα[hj |
b]
———
Pα[hi
| b] |
The second line follows if cn is no more likely
on hi·b than on
hj·b—i.e., if neither hypothesis makes the
occurrence of experimental or observation conditions more likely than the
other.[9]
This ratio form of Bayes's Theorem expresses how much more plausible, on the
evidence, one hypothesis is than an alternative. Notice that the only subjective
element affecting the ratio of posterior probabilities is the ratio of prior
probabilities. We see from this equation that the likelihood ratios
carry the full import of the evidence. The evidence influences the evaluation of
hypotheses in no other way.
Let's consider a simple example. Suppose we possess a warped coin and want to
determine its propensity for heads. We may compare two hypotheses,
h[q] and
h[r], that
propose the propensity for heads is q and r,
respectively. Let cn report that the coin is tossed
n times in the normal way, and let en
report a total m heads. Equation (9) then yields:
Pα[h[q] |
b·cn·en]
——————
Pα[h[r]
|
b·cn·en] |
= |
qm
(1−q)n−m
—————
rm
(1−r)n−m |
· |
Pα[h[q] |
b]
————
Pα[h[r] |
b] |
When, for instance, the coin is tossed n = 100 times and comes up
heads m = 72 times, the evidence for hypothesis h[1/2] as compared to
h[3/4] is given by
the likelihood ratio
[(1/2)72(1/2)28]/[(3/4)72(1/4)28] =
.000056269. So, even if prior to the evidence, one considers it 100 times more
plausible that the coin is fair than that it is warped towards heads with
propensity 3/4—i.e., even if Pα[h[1/2] |
b] / Pα[h[3/4] |
b] = 100—the evidence provided by these tosses makes the
posterior plausibility that the coin is fair only about 6/1000th as
plausible as the hypothesis that it is warped towards heads with propensity 3/4
— i.e., Pα[h[1/2] |
b·cn·en]
/ Pα[h[3/4] |
b·cn·en]
= .0056269. Thus, such evidence strongly refutes the “fairness
hypothesis” relative to the “3/4-heads-propensity hypothesis”, provided
the assessment of prior plausibilities doesn't make the latter hypothesis
too extremely implausible to begin with. Notice, however, that
strong refutation is not absolute refutation. Additional
evidence could reverse the trend towards the strong refutation of the “fairness
hypothesis”.
This example employs repetitions of the same kind of experiment — repeated
tosses of a coin. But the point holds more generally. If, as the evidence
increases, the likelihood ratios P[en |
hj·b·cn]
/ P[en |
hi·b·cn]
approach 0, then the Ratio Form of Bayes's Theorem, Equation 9, shows that the
posterior probability of hj must approach 0 as
well. The evidence comes to strongly refute hj with
little regard for its prior plausibility value. Indeed, Bayesian induction turns
out to be a version of eliminative induction, and Equation 9 begins to
illustrate this. For, suppose that hi is the true
hypothesis, and consider what happens to each of its false competitors,
hj. If enough evidence becomes available to drive
each of the likelihood ratios P[en |
hj·b·cn]
/ P[en |
hi·b·cn]
toward 0 (as n increases), then Equation 9 says that each false
hj will become effectively refuted—each of their
posterior probabilities approaches 0. As a result, the posterior probability of
hi must approach 1. The next two equations make
this clear.
If we sum the ratio versions of Bayes's Theorem in Equation 9 over all
alternatives to hypothesis hi (including the
catch-all hK, if we need one), we get the Odds Form
of Bayes's Theorem. The odds against A given
b is defined as Ωα[~A | B] =
Pα[~A |
B] / Pα[A | B]. So, we
have:
Bayes's Theorem: The Odds Form
| (10) |
Ωα[~hi
|
b·cn·en] |
= |
∑j≠i |
P[en |
hj·b·cn]
——————
P[en
|
hi·b·cn] |
· |
Pα[hj
|
b]
—————
Pα[hi
| b] |
+ |
Pα[en
|
hK·b·cn]
——————
P[en
|
hi·b·cn] |
· |
Pα[hK
|
b]
————
Pα[hi
| b] |
Notice that if a catch-all hypothesis is needed, the likelihood of evidence
relative to it will not generally enjoy the same kind of objectivity as the
likelihoods for specific, positive hypotheses. We leave the subscript α
on the likelihood for the catch-all to indicate this lack of objectivity.
Although the catch-all hypothesis may lacks objective likelihoods, the
influence of the catch-all term in Bayes's theorem diminishes as additional
positive hypotheses are articulated. That is, as new hypotheses are
discovered they are “peeled off” of the catch-all. So, when a new hypothesis
hu+1 is formulated and made explicit, the old
catch-all hK is replaced by a new catch-all,
hK*, of form
(~h1·…·~hu·~hu+1);
and the prior probability for the new catch-all hypothesis is gotten by
diminishing the prior of the old catch-all: Pα[hK*
| b] = Pα[hK
| b] − Pα[hu+1
| b]. Thus, the influence of the catch-all term should diminish
towards 0 as new alternative hypotheses are made explicit.[10]
If increasing evidence drives the likelihood ratios comparing
hi with each competitor towards 0, then the odds
against hi, Ωα[~hi |
b·cn·en],
will approach 0 (provided that priors of catch-all terms, if needed, approach 0
as well as new alternative hypotheses are made explicit and peeled off). And, as
Ωα[~hi
|
b·cn·en]
approaches 0, the posterior probability of hi goes
to 1. The relationship between the odds against hi
and its posterior probability is this:
Bayes's Theorem: The General Probabilistic
Form
(11) Pα[hi |
b·cn·en] =
1/(1 + Ωα[~hi |
b·cn·en]).
There is a result, a kind of Bayesian Convergence Theorem, that
shows that if hi (together with
b·cn) is true, then the likelihood ratios
P[en |
hj·b·cn]
/ P[en |
hi·b·cn]
comparing evidentially distinguishable alternative hypothesis
hj to hi will very
probably approach 0 as evidence accumulates (i.e., as n
increases). Let's call this result the Likelihood Ratio Convergence
Theorem. When this theorem applies, Equation 9 shows that the posterior
probability of false competitor hj will very
probably approach 0 as evidence accumulates, regardless of the value of its
prior probability Pα[hj
| b]. As this happens to each of
hi's false competitors, Equations 10 and 11 say
that the posterior probability of the true hypothesis,
hi, will very probably approach 1 as evidence
increases.[11] Thus, Bayesian induction is at bottom a version of
induction by elimination, where the elimination of alternatives comes
by way of likelihood ratios approaching 0 as evidence accumulates. We will
examine the Likelihood Ratio Convergence Theorem in detail in Section
5.[12]
For more on Bayes's Theorem see the entries on Bayes' Theorem and
on Bayesian
epistemology in this Encyclopedia.
The versions of Bayes's Theorem provided by Equations 9-11 show that for
probabilistic inductive logic the influence of empirical evidence on posterior
probabilities of hypotheses is completely captured by the ratios of likelihoods,
P[en |
hj·b·cn]
/ P[en |
hi·b·cn].
The evidence (cn·en)
influences the posterior probabilities in no other way. So, the following “Law”
is a consequence of the inductive logic of support functions.
General Law of Likelihood:
Given any pair of
incompatible hypotheses hi and
hj, whenever the likelihoods Pα[en
|
hj·b·cn]
and Pα[en
|
hi·b·cn]
are defined, the evidence
(cn·en) supports
hi over hj, given
b, if and only if Pα[en
|
hi·b·cn]
> Pα[en
|
hj·b·cn].
The ratio of likelihoods Pα[en
|
hi·b·cn]
/ Pα[en
|
hj·b·cn]
measures the strength of the evidence for
hi over hj given
b.
Two features of this law require some explanation. As stated, the
General Law of Likelihood does not presuppose that likelihoods
of form Pα[en
|
hj·b·cn]
and Pα[en
|
hi·b·cn]
are always defined. This qualification is introduced to accommodate a
conception of evidential support called Likelihoodism, which is
especially influential among statisticians. Also, the likelihoods in the law are
expressed with the subscript α attached to indicate that the law holds for each
inductive support function Pα, even when the values
of the likelihoods are not objective or agreed on by all agents in a given
scientific community. These two features of the law are closely related, as we
will see.
Each probabilistic support function satisfies the axioms of Section
2. According to these axioms the conditional probability of one sentence on
another is always defined. So, in the context of the inductive logic of
support functions the likelihoods are always defined, and the
qualifying clause about this in the General Law of Likelihood
is automatically satisfied. For inductive support functions, all of the
versions of Bayes's theorem (Equations 8-11) continue to hold even when the
likelihoods are not objective or intersubjectively agreed on by the scientific
community. Although in many scientific contexts there will be agreement on the
values of likelihoods, whenever such agreement fails, the subscripts α, β, etc.
must remain attached to the support function likelihoods to indicate this. Even
so, the General Law of Likelihood continues to hold.
There is a view, or family of views, called likelihoodism that
maintains that the inductive logician or statistician should only concern
himself with whether the evidence provides increased or decreased
support for one hypothesis over another, and only in cases where this
evaluation is based on the ratios of completely objective likelihoods.
When the likelihoods involved are objective, the ratios P[en |
hj·b·cn]
/ P[e n
|
hi·b·cn]
provide a pure, objective measure of how strongly the evidence supports
hi as compared to hj,
“untainted” by prior plausibility considerations. According to likelihoodists,
only this kind of pure measure is scientifically appropriate for the
assessment of how evidence impacts hypotheses.
Likelihoodists maintain that it is not appropriate for statisticians to
incorporate assumptions about prior probabilities of hypotheses into the
assessment of evidential support. It is not their place to compute
recommended values of posterior probabilities for the scientific
community. When the results of experiments are made public, say in scientific
journals, only objective likelihoods should be reported. The evaluation of the
impact of objective likelihoods on agents' posterior probabilities depends on
each agent's individual subjective prior probability, which represents
plausibility considerations that have nothing to do with the evidence. So,
posterior probabilities should be left to individuals to compute, if they wish
to do so.
The conditional probabilities for most pairs of sentences fail to be
objectively defined in a way that suits likelihoodists. So, for them,
the general logic of support functions (captured by the axioms of
Section 2) cannot represent an objective logic of evidential
support for hypotheses. Because they eschew the logic of support functions,
likelihoodist do not have Bayes's theorem available, and so cannot
derive the Law of Likelihood from it. Rather, they must state
the Law of Likelihood as an axiom of their
inductive logic, an axiom that applies only when the likelihoods have
well-defined objective values.
Likelihoodists tend to have a very strict conception of what it
takes for likelihoods to be well-defined. They consider a likelihood to
be well-defined only when it is what we referred to earlier as a
direct inference likelihood — i.e., only when either, (1) the
hypothesis (together with background and experimental conditions) logically
entails the data, or (2) the hypothesis (together with background) logically
entails an explicit simple statistical hypothesis that (together with
experimental conditions) specifies precise probabilities for the each of the
events that make up the evidence.
Likelihoodists contrast simple statistical hypotheses with
composite statistical hypotheses, which only entail vague, or
imprecise, or directional claims about the statistical probabilities of
evidential events. Whereas a simple statistical hypothesis might say,
for example, “ the chance of heads on tosses of the coin is precisely
.65.”, by contrast a composite statistical hypothesis might say, “ the chance of
heads on tosses is either .65 or .75,” or it may be a directional
hypothesis that says, “ the chance of heads on tosses is greater
than .65.” Likelihoodists maintain that composite hypotheses
are not an appropriate basis for well-defined likelihoods. Such hypotheses
represent a kind of disjunction of simple statistical hypotheses. The
direction hypothesis, for instance, is essentially a disjunction of the
various simple statistical hypotheses that assign specific values above
.65 to the chances of heads on tosses. Likelihoods based on such hypotheses are
not appropriately objective by the lights of the likelihoodist
because they must in effect depend on factors that represent the degree to which
the composite hypothesis supports each of the simple statistical
hypotheses that it encompasses; and likelihoodists consider such
factors too subjective to be permitted in a logic that countenances only
objective likelihoods.[13]
Taking all of this into account, the version of the Law of
Likelihood appropriate to likelihoodists may be stated as
follows.
Special Law of Likelihood:
Given a pair of
incompatible hypotheses hi and
hj that imply simple statistical models regarding
outcomes en given
(b·cn), the likelihoods P[en |
hj·b·cn]
and P[en |
hi·b·cn]
are well defined. For such likelihoods, the evidence
(cn·en) supports
hi over hj, given
b, if and only if P[en |
hi·b·cn]
> P[en |
hj·b·cn];
the ratio of likelihoods P[en |
hi·b·cn]
/ P[en
|
hj·b·cn]
measures the strength of the evidence for
hi over hj given
b.
Notice that when either version of the Law of Likelihood
holds, the absolute size of a likelihood is irrelevant to the strength of the
evidence. All that matters is the relative size of the likelihoods for one
hypothesis as compared to another. That is, let c1 and
c2 be the conditions for two distinct experiments having
outcomes e1 and e2, respectively.
Suppose that e1 is 1000 times more likely on
hi (given b·c1) than
is e2 on hi (given
b·c2); and suppose that e1 is
also 1000 times more likely on hj (given
b·c1) than is e2 on
hj (given b·c2)—i.e.,
suppose that Pα[e1 |
hi·b·c1] = 1000
· Pα[e2 |
hi·b·c1], and
Pα[e1
| hj·b·c1] =
1000 · Pα[e2 |
hj·b·c2]. Which
piece of evidence, (c1·e1) or
(c2·e2), is stronger evidence with
regard to the comparison of hi to
hj? The Law of Likelihood implies
both are equally strong. All that matters evidentially are the ratios of the
likelihoods, and they are the same: Pα[e1 |
hi·b·c1] /
Pα[e1 |
hj·b·c1] =
Pα[e2
| hi·b·c2] /
Pα[e2 |
hj·b·c2]. Thus,
the General Law of Likelihood implies the following
principle.
General Likelihood Principle:
Suppose two
different experiments or observations (or two sequences of them)
c1 and c2 produce outcomes
e1 and e2, respectively. Let {
h1, h2, …} be any set of alternative
hypotheses. If there is a constant K such that for each hypothesis
hj from the set, Pα[e1 |
hj·b·c1] =
K · Pα[e2 |
hj·b·c2], then the
evidential import of (c1·e1)
for distinguishing among hypotheses in the set (given b) is precisely the same
as the evidential import of
(c2·e2).
Similarly, the Special Law of Likelihood implies a
corresponding Special Likelihood Principle that applies only to
hypotheses that express simple statistical models.[14]
Throughout the remainder of this article we will not assume that likelihoods
must be based on simple statistical hypotheses, as likelihoodist would
have them. However, most of what will be said about likelihoods, especially the
convergence result in Section 5, applies to likelihoodist likelihoods
as well. We will, however, continue to suppose that likelihoods are
objective in the sense that all members of the scientific community
agree on their numerical values. In Section 6 we will see how to even relax this
supposition for those contexts where it is unrealistic.
Given that a scientific community should largely agree on the values of the
likelihoods, any significant disagreement regarding the posterior plausibilities
of hypotheses should derive from disagreements over prior plausibilities.
Furthermore, individual agents may be unable to specify precisely how
plausible they consider hypotheses to be; so their prior probabilities for
hypotheses may be vague. Both disagreements among agents and vagueness for
individual agents can be represented formally by sets of inductive support
functions, {Pα, Pβ, …}, that agree on
the values for the likelihoods, but encompass a range of values for the prior
plausibilities of hypotheses. Disagreement and vagueness are
different issues, but they may be represented in much the same way. Let us
consider them in turn.
Assessments of evidence-independent plausibilities of hypotheses by real
people will often be vague, and not subject to the kind of precise quantitative
treatment that a Bayesian version of probabilistic inductive logic seems to
require for prior probabilities. So, it is sometimes objected, the kind of
assessment of prior probabilities required to get the Bayesian algorithm going
cannot be accomplished in practice. Bayesian inductivists have a way of
addressing this worry. An agent's vague assessments of prior plausibilities may
be represented by a collection of probability functions, a vagueness
set, which covers the range of plausibility values that the agent finds
acceptable. Notice that if accumulating evidence drives the likelihood ratios to
extremes, the range of functions in the agent's vagueness set will come
to near agreement, near 0 or 1, on values for posterior probabilities of
hypotheses. Thus, as evidence accumulates, the agent's vague initial
plausibility assessments transform into quite sharp posterior probabilities that
indicate the strong refutation or support of the various hypotheses. Intuitively
this seems a quite reasonable effect.
The various agents in a community may widely disagree over the non-evidential
plausiblities of hypotheses. Bayesian inductivists may represent this kind of
diversity across the community of agents as a collection of the agents'
vagueness sets. Let's call such a collection a Diversity set.
So, although there may well be disagreement among agents regarding the prior
plausibilities of hypotheses, and only vague priors for individual agents,
probabilistic inductive logic may easily represent this. Furthermore, if
accumulating evidence drives the likelihood ratios to extremes, the range of
functions in a Diversity set will come to near agreement, near 0 or 1,
on the values for posterior probabilities of hypotheses. So, not only would such
evidence firm up each agent's vague initial plausibilities, it would
also bring the whole community into agreement on the near refutation or strong
support of the various alternative hypotheses.
Under what conditions might the likelihood ratios go to such extremes as
evidence accumulates, effectively washing out vagueness and diversity? The
Likelihood Ratio Convergence Theorem (discussed in detail in Section 5)
implies that if a true hypothesis disagrees with false alternatives on the
likelihoods of possible outcomes for a long enough stream of
experiments or observations, then that evidence stream will very probably
produce actual outcomes that drive the likelikood ratios of false
alternative as compared to the true hypothesis to approach 0. As this happens,
almost any range of prior plausibility assessments will be driven to agreement
on the posterior plausibilities for hypotheses. Thus, the accumulating evidence
will very probably bring all support functions in the vagueness and
Diversity sets for a community of agents to near agreement on posterior
plausibility values — near 0 for the false competitors, and near 1 for the true
hypothesis.
One more point about prior probabilities and Bayesian convergence should be
mentioned. Some subjectivist versions of Bayesian induction seem to suggest that
an agent's prior plausibility assessments for hypotheses should stay fixed once
and for all, and that all plausibility updating should be brought about via the
likelihoods in accord with Bayes's Theorem. Critics argue that this is
unreasonable. The members of a scientific community may quite legitimately
revise their prior plausibility assessments for hypotheses from time to time as
they rethink plausibility arguments and bring new considerations to bear. This
seems a natural part of the conceptual development of a science. It turns out
that such reassessments of priors pose no difficulty for probabilistic inductive
logic. Reassessments may sometimes come about by the addition of explicit
statements that supplement or modify the background information b. They
may also take the form of (non-Bayesian) transitions to new vagueness
sets for individual agents and to new Diversity sets for the
community. The logic of Bayesian induction has nothing to say about
what values the prior plausibility assessments for hypotheses should have; and
it places no restrictions on how they might change. Provided that the series of
reassessments of prior plausibilities doesn't push the prior of the true
hypothesis ever nearer to zero, the Likelihood Ratio Convergence
Theorem implies that the evidence will very probably bring the posterior
probabilities of empirically distinct rivals of the true hypothesis to approach
0 via decreasing likelihood ratios; and as this happens, the posterior
probability of the true hypothesis will head towards 1.
4. Bayesian Estimation and Convergence for Enumerative
Inductions
In this section we'll see that for the special case of enumerative inductions
probabilistic inductive logic satisfies the Criterion of Adequacy (CoA) stated
at the beginning of this article. That is, under some plausible conditions,
given a reasonable amount of evidence, the degree to which that
evidence comes to support a hypothesis through enumerative induction is
very likely to approaches 1 for true hypotheses. We will now see how this
works.
Recall that in enumerative inductions the idea is to infer the proportion, or
relative frequency, of an attribute in a population from how frequently
the attribute occurs in a sample of the population. Examples 1 and 2 at the
beginning of the article describe two such inferences. Enumerative induction is
only a rather special case of inductive inference. However, such inferences are
very common, and so worthy of carefully attention. They arise, for example, in
the context of polling, and in many other cases where a population frequency is
estimated from a sample. We will establish conditions under which such
inferences give rise to highly objective posterior probabilities, posterior
probabilities that are fairly stable over a wide range of reasonable prior
plausibility assessments. That is, consider all of the inductive support
functions in an agent's vagueness set V or in a community's
diversity set D. We will see that under some very weak suppositions
about the make up of V or of D, a reasonable amount of data
will bring all of the support functions in these sets to agree that the
posterior degree of support for a hypothesis is very close to 1. And, we will
see, it is very likely these support functions will convergence to agreement on
a true hypothesis.
Suppose we want to know the frequency with which attribute A occurs
among members of population B. We randomly select a sample S
from B consisting of n members, and find that it contains m
members having attribute A.[15] On the basis of this evidence, what posterior
probability p can we find for the hypothesis that the true proportion (or
frequency) of A among B is within a given margin q
around the sample proportion m/n? And to what extent does that
bound depend on the prior probabilities of the various possible alternative
frequency hypotheses. More generally, for a given vagueness or
diversity set, what lower bound can we place on p.
Put more formally, we are asking for what values of p and q
does the following inequality hold?:
Pα[ (m/n)−q <
F[A,B] < (m/n)+q |
b ·
F[A,B∩S]=m/n ·
Random[S,B,A] · Size[S]=n] >
p.
It turns out that we need only one very weak assumption about the values of
prior probabilities of support functions Pα in
vagueness or diversity sets to legitimize such inferences, an
assumption that almost always holds in the context of enumerative
inductions.
Boundedness Assumption for Estimation:
There
is a region R of possible values near the sample frequency
m/n (e.g., R is the region between
(m/n)−q and (m/n)+q ,
for some margin q of interest) such that no frequency hypothesis
outside of R is overwhelmingly more initially plausible than
frequency hypotheses inside of R.
What does it mean for a hypothesis to not be overwhelmingly initially more
plausible than another? Let's be precise. Consider two kinds of cases:
Case 1. Suppose there is a known upper bound w on the
size of the whole population B (where w is much larger than the
sample size n). In that case we just need the following two
conditions to hold for all support functions Pα in the
vagueness or diversity set under consideration.
- There is some small g > 0 (as small as you like) such that
all hypotheses of form F[A,B] =
k/w in region R have prior probabilities
greater than g—i.e., Pα[F[A,B]
= k/w | b] > g for each
k/w in R, for all Pα under
consideration.
- There is a factor η (possibly very large) such that all hypotheses of
form F[A,B] =
k/w not in region R have prior
probabilities no larger than η·g—i.e., Pα[F[A,B]
= k/w | b] < η·g for each
k/w not in R, for all support functions
Pα under consideration.
(We also assume, as seems reasonable, that in the absence of information
about the observed sample frequency, the claim
‘Random[S,B,A] · Size[S]=n’ (that
the sample is randomly selected and of size n) should be irrelevant to the
probabilities of possible population frequencies. Thus, we suppose that Pα[F[A,B]
= k/w | Random[S,B,A] ·
Size[S]=n · b] = Pα[F[A,B]
= k/w | b].)
Case 2. Alternatively, suppose that no positive integer w is known
to be an upper bound on the possible values of the population size. But
suppose that the prior probabilities of the various competing hypotheses can
be represented (at least very nearly) by a probability density function pα[F[A,B]
= r | b] — i.e., for any specific values v
and u, Pα[
v < F[A,B] < u |
b] = ∫vu
pα[F[A,B] = r |
b] dr. Then we just need the following two conditions
to be satisfied by all support functions Pα in the
vagueness or diversity set under consideration.
- There is some small g > 0 (as small as you like) such that
the density function pα[F[A,B]
= r | b] is never less than g for
r inside region R.
- There is a factor η (possibly quite large) such that pα[F[A,B]
= r | b] is never more than η·g for
r outside of region R.
(We also assume, as seems reasonable, that in the absence of information
about the observed sample frequency, the claim
‘Random[S,B,A] · Size[S]=n’ (that
the sample is randomly selected and of size n) should be irrelevant to the
values of the probability density function for population frequencies. Thus, we
suppose that pα[F[A,B]
= q | Random[S,B,A] ·
Size[S]=n · b] = pα[F[A,B]
= s | b].)
When either of these conditions is satisfied let us say that for the support
functions Pα in the vaguness or diversity
set under consideration, the prior probabilities are
(g,η) bounded for region R . Then we have the
following theorem about enumerative inductions.
Theorem: Simple Estimation Theorem:[16]
Suppose, for all support functions
Pα in the vaguness or diversity set
under consideration, the prior probabilities are (g,η) bounded for
region R around m/n. Then, for all support
functions Pα in the vagueness or diversity
set,
Pα[
F[A,B]∈R | b ·
F[A,B∩S]=m/n ·
Random[S,B,A] · Size[S]=n] ≥
1/(1+ η · [(1/Beta[m+1, n−m+1, R]) − 1]).
For any given value of m/n, this lower bound approaches 1
rapidly as n increases.
The expression ‘Beta[m+1, n−m+1, R]’
represents the beta function with parameters m+1 and
n−m+1 evaluated over region R. By definition
Beta[m+1, n−m+1, R] = ∫R
rm (1−r)n−m
dr / ∫01 r m
(1−r)n−m dr. When region
R contains an interval around m/n, the value of
this function is a fraction that approaches 1 for large n. (Its
values may be easily computed using the beta function contained in any
sophisticated mathematics or spreadsheet program.)
This theorem implies that for large samples the values of prior probabilities
don't matter much. Given such evidence, a vary wide range of inductive support
functions Pα will come to agree on high posterior
probabilities that the proportion of attribute A in population
B is very close to the sample frequency. Thus, all support functions in
such vagueness or diversity sets come to near agreement. Let
us look at several numerical examples to make clear how strong this result
really is.
At the beginning of this article we saw two examples of enumerative inductive
inferences. Consider Example 1. Let ‘B’ represent the population of all
ravens. Let ‘A’ represent the class of black ravens. Now consider those
hypotheses of form ‘F[A,B] =
r’ for r in the interval between .99 and 1. This
collection of hypotheses includes the claim that “all ravens are black” together
with those alternative hypotheses that claim the frequency of being black among
ravens is within .01 of 1. The alternatives to these hypotheses are just those
that assert ‘F[A,B]
= s’ for values of s below .99.
Suppose none of the support functions represented in the vagueness
or diversity set under consideration rates the prior plausibility of
any of the hypotheses ‘F[A,B] =
s’ with s less than .99 to be more than twice as
plausible as the hypotheses ‘F[A,B] =
r’ for which r is between .99 and 1. That is, suppose, for
each Pα in the vagueness or diversity set
under consideration, the prior plausibility Pα[F[A,B]
= s | b] for hypotheses with s below .99 is
never more than η = 2 times greater than the prior plausibility Pα[F[A,B]
= r | b] for hypotheses with r between .99 and
1. Then, on the evidence of 400 ravens selected randomly with respect to color,
the theorem yields the following bound for all Pα in the
vagueness or diversity set:
Pα[F[A,B]
> .99 | b · F[A,B∩S] = 1 ·
Random[S,B,A] · Size[S] = 400] ≥
.9651.
The following table describes similar results for other prior probability
ratios and sample sizes n:
m/n = 1
F[A,B]> .99 |
|
Sample-Size = n
(number of As in Sample of Bs = m =
n) |
Prior Ratio: η
↓ |
|
400 |
800 |
1600 |
3200 |
|
|
|
|
|
|
| 1 |
|
0.9822 |
0.9997 |
1.0000 |
1.0000 |
| 2 |
|
0.9651 |
0.9994 |
1.0000 |
1.0000 |
| 5 |
|
0.9170 |
0.9984 |
1.0000 |
1.0000 |
| 10 |
|
0.8468 |
0.9968 |
1.0000 |
1.0000 |
| 100 |
|
0.3560 |
0.9691 |
1.0000 |
1.0000 |
| 1,000 |
|
0.0524 |
0.7581 |
0.9999 |
1.0000 |
| 10,000 |
|
0.0055 |
0.2386 |
0.9990 |
1.0000 |
| 100,000 |
|
0.0006 |
0.0304 |
0.9898 |
1.0000 |
| 1,000,000 |
|
0.0001 |
0.0031 |
0.9068 |
1.0000 |
| 10,000,000 |
|
0.0000 |
0.0003 |
0.4931 |
1.0000 |
Table 1: Values of lower bound p on the posterior
probability
Pα[F[A,B]
> .99 | b · F[A,B∩S]=1 ·
Random[S,B,A] · Size[S]=n]
≥ p,
for a range of Sample-Sizes n (from 400 to 3200), when the prior
probability of any specific frequency hypothesis outside the region between
.99 and 1 is no more than η times more than the lowest prior probability for
any specific frequency hypothesis inside of the region between .99 and
1.
(All probabilities with entries ‘1.0000’ in this table and the next actually
have values slightly less than one, but nearly equal 1.0000 to four significant
decimal places.)
To see what the table tells us, consider the third to last row. It represents
what happens when a vagueness or diversity set contains at
least some support functions that assign prior plausibilities nearly one
hundred thousand times higher to some hypotheses asserting frequencies
not between .99 and 1 than it assigns to hypotheses asserting
frequencies between .99 and 1. The table shows that even in such cases, a random
sample of 1600 black ravens will, nevertheless, pull the posterior plausibility
level that “the true frequency is above .99” to a value above .9898, for every
support function in the set. And if the vagueness or diversity
set contains support functions that assign even more extreme priors, say, priors
that are nearly ten million times higher for some hypotheses asserting
frequencies below .99 than for hypotheses within .99 of 1 (the table's last
row), this poses no great problem for convergence-to-agreement. A random sample
of 3200 black ravens will yield posterior plausibilities indistinguishable from
1 for the claim that “more than 99% of all ravens are black.”
Strong support can be gotten for an even narrower range of hypotheses about
the percentage of black birds among the ravens. But a larger sample size is
needed for this. For an additional example, see the supplementary document
Tighter Bounds on the Margin of Error.
Consider the second example from the beginning of this article, the poll
about the presidential preferences of voters. The posterior plausibilities for
this example follow a similar pattern. That is, let ‘B’ represent the
class of all registered voters on February 20, 2004, and let ‘A’
represent those who prefer Kerry to Bush. In sample S (randomly drawn
from B with respect to A) consisting of 400 voters, 248 report
preference for Kerry over Bush — i.e., F[A,B] = 248/400 =
.62. Suppose, as seems reasonable, that none of the support functions in the
vagueness or diversity set under consideration rates the
hypotheses ‘F[A,B] =
r’ for values of r outside the interval .62±.05 as
more initially plausible than they rate alternative frequency
hypotheses having values of r inside this interval. That is, suppose,
for each Pα under consideration, the prior plausibilities
Pα[F[A,B]
= s | b] when s is not within .62±.05
is never more than η = 1 times as great as the prior plausibilities Pα[F[A,B]
= r | b] for hypotheses having r within
.62±.05. Then, the theorem yields the following lower bound on the posterior
plausibility ratings, for all Pα in the vagueness
or diversity set under consideration:
Pα[.57 <
F[A,B] < .67 | b ·
F[A,B∩S]=.62 ·
Random[S,B,A] · Size[S]=400] ≥
.9614.
The following table gives similar results for other sample sizes and for
ratios of prior plausibilities that may be much larger than 1. In addition, this
table shows what happens when we tighten up the interval around the frequency
hypotheses being supported to .62±.025—i.e., it shows the bounds p on
support for the hypothesis .595< F[A,B] < .645
as well:
| m/n = .62 |
F[A,B] =
m/n ±
q |
|
Sample-Size = n
(number of
As in Sample of Bs = m: where
m/n = .62) |
Prior Ratio: η
↓ |
q =
.05 or .025 |
|
400
(248) |
800
(496) |
1600
(992) |
3200
(1984) |
6400
(3968) |
12800
(7936) |
|
|
|
|
|
|
|
|
|
| 1 |
.05 →
.025 → |
|
0.9614
0.6982 |
0.9965
0.8554 |
1.0000
0.9608 |
1.0000
0.9964 |
1.0000
1.0000 |
1.0000
1.0000 |
| 2 |
.05 →
.025 → |
|
0.9256
0.5364 |
0.9930
0.7474 |
0.9999
0.9246 |
1.0000
0.9929 |
1.0000
0.9999 |
1.0000
1.0000 |
| 5 |
.05 →
.025 → |
|
0.8327
0.3163 |
0.9827
0.5420 |
0.9998
0.8306 |
1.0000
0.9825 |
1.0000
0.9998 |
1.0000
1.0000 |
| 10 |
.05 →
.025 → |
|
0.7133
0.1879 |
0.9661
0.3717 |
0.9996
0.7103 |
1.0000
0.9656 |
1.0000
0.9996 |
1.0000
1.0000 |
| 100 |
.05 →
.025 → |
|
0.1992
0.0226 |
0.7402
0.0559 |
0.9963
0.1969 |
1.0000
0.7371 |
1.0000
0.9962 |
1.0000
1.0000 |
| 1,000 |
.05 →
.025 → |
|
0.0243
0.0023 |
0.2217
0.0059 |
0.9639
0.0239 |
1.0000
0.2190 |
1.0000
0.9637 |
1.0000
1.0000 |
| 10,000 |
.05 →
.025 → |
|
0.0025
0.0002 |
0.0277
0.0006 |
0.7277
0.0024 |
0.9999
0.0273 |
1.0000
0.7261 |
1.0000
0.9999 |
| 100,000 |
.05 →
.025 → |
|
0.0002
0.0000 |
0.0028
0.0001 |
0.2109
0.0002 |
0.9994
0.0028 |
1.0000
0.2096 |
1.0000
0.9994 |
| 1,000,000 |
.05 →
.025 → |
|
0.0000
0.0000 |
0.0003
0.0000 |
0.0260
0.0000 |
0.9940
0.0003 |
1.0000
0.0258 |
1.0000
0.9943 |
| 10,000,000 |
.05 →
.025 → |
|
0.0000
0.0000 |
0.0000
0.0000 |
0.0027
0.0000 |
0.9433
0.0000 |
1.0000
0.0026 |
1.0000
0.9457 |
Table 2: Values of lower bound p on the posterior
probability
Pα[.62−q <
F[A,B] < .62+q |
F[A,B∩S] = .62 ·
Random[S,B,A] · Size[S] =
n] ≥ p,
for two values of q (.05 and .025) and a range of Sample-Sizes
n (from 400 to 12800), when the prior probability of any specific
frequency hypothesis outside of .62 ± q is no more than η times more
than the lowest prior probability for any specific frequency hypothesis inside
of .62 ± q.
Notice that even if the vagueness or diversity set includes
prior plausibilities nearly ten million times higher for hypotheses
asserting frequency values outside of .62±.025 than for hypotheses
asserting frequencies within .62±.025, a random sample of 12800
registered voters will, nevertheless, bring about a posterior plausibility value
greater than .9457 for the claim that “the true frequency of preference for
Kerry over Bush among all registered voters is within .62±.025”, for all support
functions Pα in the set.
The Simple Estimation Theorem is a Bayesian Convergence-to-Agreement result.
However, it does not show that the Criterion of Adequacy (CoA) is satisfied. The
theorem shows, for enumerative inductions, that as evidence accumulates, diverse
support functions will come to near agreement on high posterior support
strengths for those hypotheses expressing population frequencies near the sample
frequency. But, it does not show that the true hypothesis is among them—it does
not show that sample frequency is near the true population frequency. So, it
does not show that these converging support functions converge on strong support
for the true hypothesis, as a CoA result is supposed to do.
However, there is such a CoA result close at hand. It derives from an
application of the Central Limit Theorem. It establishes that each
frequency hypothesis of form ‘F[A,B] =
r’ implies, via direct inference likelihoods, that
randomly selected sample data is highly likely to result in sample frequencies
very close to the value r that it claims to be the true
frequency. Of course each frequency hypothesis says that the sample
frequency will be near its own frequency value; but only the true
hypothesis says this truthfully. Add this result to the previous theorem and we
get that, for large sample sizes, it is very likely that a sample frequency will
occur that yields a very high degree of support for the true hypothesis. Thus
the CoA is satisfied.
Here is the needed result.
Theorem: A Weak Law of Large Numbers for Enumerative
Inductions.
Let sample size n be greater than 20, and
let r be any frequency between 0 and 1. Then, for any chosen margin
q,
P[r−q <
F[A,B∩S] < r+q |
F[A,B] = r ·
Random[S,B,A] · Size[S] = n]
≈ 1 − 2 ·
Φ[−q/(r·(1−r))/n)½] ≥ 1 − 2 ·
Φ[−2·q·n½],
which goes to 1 fairly quickly as n increases.
Φ[x] is the area under the Standard Normal Distribution up to
point x. The approximation to the normal distribution is very close
for n > 20, and gets closer as n gets
larger.
Notice that the degree of support probability in this theorem is a direct
inference likelihood—all support functions should agree on these
values.[17]
This Weak Law result together with the Simple Estimation Theorem yields the
promised CoA result: for large sample sizes, it is very likely that a sample
frequency will occur that has a value very near the true frequency; and whenever
such a sample frequency does occur, it yields a very high degree of support for
the true frequency hypothesis.
This result only applies to enumerative inductions. In the next section we
establish a CoA result that applies much more generally. It applies to the
inductive support of hypotheses in any context where competing hypotheses are
empirically distinct enough to disagree, at least a little, on the likelihoods
of possible outcomes.
In this section we will investigate the Likelihood Ratio Convergence
Theorem. This theorem shows that under reasonable conditions, when
hi is true and hj is
empirically distinct from hi, then it is very
likely that a sequence of outcomes en will
occur that yields likelihood ratios P[en |
hj·b·cn]
/ P[en |
hi·b·cn]
that approach 0 as evidence accumulates (i.e., as n increases). The
theorem places an explicit lower bound on the “rate of probable convergence” of
likelihood ratios towards 0. That is, it puts a lower bound on how likely it is,
if hi is true, that a stream of outcomes will occur
that yields a likelihood ratio against hj within a
specified small distance from 0.
The theorem itself is not strictly Bayesian. It draws only on likelihoods.
Neither the statement of the theorem nor its proof employ prior probabilities of
any kind. Likelihoodists and Bayesian inductivists agree that when the ratios
P[en |
hj·b·cn]
/ P[en |
hi·b·cn]
approach 0 for increasing n, the evidence goes strongly against
hj as compared to hi.
So even a likelihoodist who eschews the use of Bayesian prior
probabilities may embrace this result.
For Bayesians, the Likelihood Ratio Convergence Theorem further
implies the likely convergence to agreement (near 0) of the posterior
probabilities of false competitors of a true hypothesis. When the ratios P[en |
hj·b·cn]
/ P[en |
hi·b·cn]
approach 0 for increasing n, the Ratio Form of Bayes's Theorem,
Equation 9, says that the posterior probability of
hj must also approach 0 as evidence accumulates,
regardless of the value of its prior probability. So, support functions in
collections representing vague prior plausibilities for an individual agent
(i.e., a vagueness set) and representing the diverse range of priors
for a community of agents (i.e., a diversity set) will very likely come
to agree on the near 0 posterior probability of empirically distinct false
rivals of a true hypothesis. And as the posterior probabilities of false
competitors fall, the posterior probability of the true hypothesis heads towards
1. Thus, the theorem establishes that the inductive logic of probabilistic
support functions satisfies the Criterion of Adequacy (CoA).
The Likelihood Ratio Convergence Theorem overcomes many of the
objections raised by critics of Bayesian convergence results. First, this
theorem does not employ second-order probabilities; it says noting
about the probability of a probability. It only concerns the probability of a
particular disjunctive sentence expressing possible sequences of outcomes. The
theorem does not require evidence to consist of sequences of events that,
according to the hypothesis, are identically distributed (like repeated tosses
of a die). A version of the theorem even applies when the observations that make
up the evidence stream are not probabilistically independent on the hypotheses.
The result does not rely on countable additivity, and the explicit lower bounds
it provides on convergence means that there is no need to wait for the infinite
long run.
It is sometimes claimed that Bayesain convergence results only work when an
agent locks in values for the prior probabilities of hypotheses once and for
all, and updates posterior probabilities from there only by conditionalizating
on evidence via Bayes Theorem. The Likelihood Ratio Convergence
Theorem, however, applies even if agents revise their prior plausibility
assessments over time. Such non-Bayesian shifts from one support function or
vagueness set to another may arise from new non-evidential plausibility
arguments, or may be due to reassessments of old ones. The Likelihood Ratio
Convergence Theorem itself only involves the values of likelihoods. So,
provided such reassessments don't push the prior plausibility of the true
hypothesis towards 0 too rapidly, the theorem implies that the
posterior probabilities of each empirically distinct false competitor will
very probably approach 0 as evidence increases.[18]
To specify the details of the Likelihood Ratio Convergence Theorem
we'll need a few additional notational conventions and definitions. Here they
come.
For a given sequence of n experiments or observations
cn, consider the set of those possible sequences of
outcomes that would result in likelihood ratios for
hj over hi that are
less than some chosen small number ε > 0. This set is represented by the
expression:
{en :
P[en |
hj·b·cn] /
P[en |
hi·b·cn]
< ε}
Placing the disjunction symbol ‘’ in front of this expression yields an
expression:
{en :
P[en |
hj·b·cn] /
P[en |
hi·b·cn]
< ε},
that represents the disjunction of all outcome sequences in this set. So,
{en :
P[en |
hj·b·cn] /
P[en |
hi·b·cn]
< ε}
is just a particular sentence that says, in effect, “one of the sequences of
outcomes of the first n experiments or observations will occur that
makes the likelihood ratio for hj over
hi less than ε.”
The Likelihood Ratio Convergence Theorem says that under fairly weak
assumptions, the likelihood of a disjunctive sentence of this sort, given that
‘hi·b·cn’ is
true,
P[{en :
P[en |
hj·b·cn]/P[en
| hi·b·cn]
< ε} |
hi·b·cn],
must be at least 1−(ψ/n), for some explicitly calculable term ψ.
Thus, the true hypothesis hi implies that as the
amount of evidence, n, increases, it is highly likely (as close to 1 as you
please) that one of the outcome sequences en will
occur that yields a likelihood ratio P[en |
hj·b·cn]
/ P[en |
hi·b·cn]
less than ε, for any value of ε you may choose. As this happens, the posterior
probability of hi's false competitor,
hj, must approach 0, as required by the Ratio Form
of Bayes's Theorem, Equation 9.
The term ψ in the theorem depends on a measure of the empirical distinctness
of the hypotheses for the proposed sequence of experiments and observations. To
specify this measure we need to contemplate the collection of possible outcomes
of each experiment or observation. So, consider some sequence of experimental or
observational conditions described by sentences
c1,c2,…,cn.
Corresponding to each condition ck there will be some range
of possible alternative outcomes. Let Ok =
{ok1,ok2,…,okw}
be a set of statements describing the alternative possible outcomes for
condition ck. (The number of alternative outcomes
will usually differ for distinct experiments
c1,…,cn; so, the value of
w depends on ck). For each hypothesis
hj, the alternative outcomes of
ck in Ok are mutually
exclusive and exhaustive, so we have:
| P[oku·okv
|
hj·b·ck]
= 0 |
and |
w
∑
u=1 |
P[oku |
hj·b·ck]
= 1. |
We now let expressions like ‘ek’ act as
variables that range over the possible outcomes of
ck — i.e., ek ranges
over the members of Ok. As before,
‘cn’ denotes the conjunction of the first
n test conditions,
(c1·c2·…·cn),
and ‘en’ represents possible sequences of
corresponding outcomes,
(e1·e2·…·en).
The set of all such outcome sequences is en. So,
for each hypothesis hj (including
hi), ∑en∈en
P[en |
hj·b·cn]
= 1.
In many scientific contexts the outcomes in a stream of experiments or
observations are probabilistically independent of one another relative
to each hypothesis under consideration. For our purposes independence
may be divided into two types.
Definition: Independent Evidence Conditions:
(1) A
sequence of outcomes ek is
condition-independent of a condition for an additional
experiment or observation ck+1, given
h·b and its own conditions ck,
if and only if P[ek |
h·b·ck·ck+1]
= P[ek
| h·b·ck].
(2) An individual outcome ek is
result-independent of a sequence of other observations and
their outcomes (ck−1·ek−1),
given h·b and its own condition
ck, if and only if P[ek |
h·b·ck·(ck−1·ek−1)]
= P[ek
|
h·b·ck].
When these two conditions hold, the likelihood for an evidence sequence may
be decomposed into the product of the likelihoods for individual experiments or
observations. To see how the two independence conditions affect the
decomposition, first consider the following formula, which holds even when
neither independence condition is satisfied:
| (12) |
P[en |
hj·b·cn] |
= |
n
Π
k=1 |
P[ek |
hj·b·cn·ek−1]. |
When condition-independence holds, the likelihood of the whole
evidence stream parses into a product of likelihoods that probabilistically
depend on only past observation conditions and their outcomes. They do not
depend on the conditions for other experiments whose outcomes are not yet
specified. Here is the formula:
| (13) |
P[en |
hj·b·cn] |
= |
n
Π
k=1 |
P[ek |
hj·b·ck·
(ck−1·ek−1)]. |
Finally, whenever both independence conditions are satisfied we have
the following relationship between the likelihood of the evidence stream and the
likelihoods of individual experiments or observations:
| (14) |
P[en |
hj·b·cn] |
= |
n
Π
k=1 |
P[ek |
hj·b·ck]. |
(For proofs of Equations 12-14, see the supplementary document: Immediate Consequences of Independent Evidence
Conditions.)
In many scientific contexts both clauses of the Independent Evidence
Condition will be satisfied. Let us consider each independence condition
more carefully.
Condition-independence says that the mere addition of a new
observation condition ck+1, without specifying
one of its outcomes, does not alter the likelihood of the outcomes
ek of other experiments
ck. To appreciate the significance of this
condition, imagine what it would be like if it were violated. Suppose hypothesis
hj is some statistical theory, say, for example, a
quantum theory of superconductivity. The conditions expressed in
ck describe a number of experimental setups,
perhaps conducted in numerous labs throughout the world, that test a variety of
aspects of the theory (e.g., experiments that test electrical conductivity in
different materials at a range of temperatures). An outcome sequence
ek describes the results of these experiments. The
violation of condition-independence would mean that merely adding to
hj·b·ck a
statement ck+1 describing how an additional
experiment has been set up, but with no mention of its outcome, changes how
likely the evidence sequence ek is taken to be.
What (hj·b) says via likelihoods
about the outcomes ek of experiments
ck differs as a result of merely supplying a
description of another experimental arrangement,
ck+1. Condition-independence, when it
holds, rules out such strange effects.
Result-independence says that the description of previous test
conditions together with their outcomes is irrelevant to the
likelihoods of outcomes for additional experiments. If this condition were
widely violated, then in order to specify the most informed likelihoods for a
given hypothesis one would need to include information about volumes of past
observations and their outcomes. What a hypothesis says about future cases would
depend on how past cases have gone. Such dependence had better not
happen on a large scale. Otherwise, the hypothesis would be fairly useless,
since its empirical import in each specific case would depend on taking into
account volumes of past observational and experimental results. However, even if
such dependencies occur, provided they are not too pervasive,
result-independence can be accommodated rather easily by packaging each
collection of result-dependent data together, treating it like a single
extended experiment or observation. The result-independence condition
will then be satisfied by letting each term ‘ck’ in
the statement of the independence condition represent a conjunction of test
conditions for a collection of result-dependent tests, and by letting
each term ‘ek’ (and each term
‘oku’) stand for a conjunction of the corresponding
result-dependent outcomes. Thus, by packaging result-dependent
data together in this way, the result-independence condition is
satisfied by those (conjunctive) statements that describe the separate,
result-independent chunks.[19]
The version of the Likelihood Ratio Convergence Theorem we will
examine depends only on the Independent Evidence Conditions and on the
axioms of probability theory. It draws on no other assumptions. Indeed, an even
more general version of the theorem can be established that draws on neither of
the Independent Evidence Conditions. However, the Independent
Evidence Conditions are very plausible in many scientific contexts. So,
little will be lost by assuming them. And the presentation will run more
smoothly if we side-step the added complications needed to explain the more
general result.
(A version of the more general theorem is stated and proved in a
Supplement to the present article. Links to this supplementary
materal occur immediately following the statements of the various parts of the
Convergence Theorem.)
From this point on let us assume that the following versions of the
Independent Evidence Conditions hold.
Assumption: Independent Evidence Assumptions. For each
hypothesis h and background b under consideration, we assume
that the experiments and observations can be packaged into condition
statements, c1,…, ck,
ck+1,…, and possible outcomes in a way that
satisfies the following conditions:
(1) Each sequence of possible outcomes ek of a
sequence of conditions ck is
condition-independent of additional conditions
ck+1—i.e., P[ek |
h·b·ck·ck+1]
= P[ek
| h·b·ck].
(2) Each possible outcome ek of condition
ck is result-independent of
sequences of other observations and possible outcomes
(ck−1·ek−1)—i.e.,
P[ek |
h·b·ck·(ck−1·ek−1)]
= P[ek
|
h·b·ck].
We now have all that is needed to begin to state the Likelihood Ratio
Convergence Theorem.
The Likelihood Ratio Convergence Theorem comes in two parts. The
first part applies whenever some of the experiments or observations in sequence
cn have possible outcomes that have 0 likelihoods
on hypothesis hj but non-0 likelihoods on
hi. Such outcomes are highly desirable. If they
occur, the likelihood ratio comparing hj to
hi will become 0, and
hj will be falsified. Crucial
experiments are a special case of this, the case where, for at least one
possible outcome oku, P[oku |
hi·b·ck]
= 1 and P[oku |
hj·b·ck]
= 0. In the more general case hi together with
b says that one of the outcomes of ck is
at least minimally probable, whereas hj says that
outcome is impossible—i.e., P[oku |
hi·b·ck]
> 0 and P[oku |
hj·b·ck]
= 0.
Likelihood Ratio Convergence Theorem 1—The Falsification
Theorem:
Suppose cm, a subsequence
of the whole evidence sequence cn, consists of
experiments or observations with the following property: there are outcomes
oku of each
ck in cm deemed
impossible by hj·b but deemed
possible by hi·b to at
least some small degree δ. That is, suppose there is a δ > 0 such that for
each ck in cm, P[{oku :
P[oku |
hj·b·ck] =
0} |
hi·b·ck]
≥ δ. Then,
| P[{en :
P[en|
hj·b·cn]/P[en
|
hi·b·cn]
= 0} |
hi·b·cn]
|
= |
P[{en :
P[en|
hj·b·cn]
= 0} |
hi·b·cn] |
|
≥ |
1−(1−δ)m,
which approaches 1 for large
m. |
(For the proof, see the supplementary document Proof of the Falsification Theorem.)
In other words, suppose hi says observation
ck has at least a small likelihood of producing one
of the outcomes oku that
hj says is impossible — i.e., P[{oku:
P[oku |
hj·b·ck] =
0} |
hi·b·ck]
≥ δ > 0. And suppose that some number m of experiments or observations are of
this kind. If the number of such observations is large enough, and
hi (together with
b·cn) is true, then it is highly likely
that one of the outcomes held to be impossible by
hj will occur, and the likelihood ratio of
hj over hi will then
become 0. Bayes's Theorem says that when this happen
hj is absolutely refuted—its posterior probability
becomes 0.
The Falsification Theorem is very commonsensical. First, notice that if there
is a crucial experiment in the evidence stream, the theorem is
completely obvious. That is, suppose for the specific experiment
ck (in evidence stream
cn) there are two incompatible possible outcomes
okv and oku such that
P[okv |
hj·b·ck]
= 1 and P[oku |
hi·b·ck]
= 1. Then, clearly, P[{oku:
P[oku |
hj·b·ck] =
0} |
hi·b·ck]
= 1, since oku is one of the
oku such that P[oku |
hj·b·ck]
= 0. So where there is a crucial experiment available, the theorem applies with
m = 1 and δ = 1.
The theorem is equally commonsensical for cases where there is no crucial
experiment. To see what it says in such cases, consider an example. Let
hi be some theory that implies a specific rate of
proton decay, but a rate so low that there is only a very small probability that
any particular proton will decay in a given year. Consider an alternative theory
hj that implies that protons never decay.
If hi is true, then for a persistent enough
sequence of observations (i.e., if proper detectors can be built and billions of
protons kept under observation for long enough), eventually a proton decay will
almost surely be detected. When this happens, the likelihood ratio becomes 0.
Thus, the posterior probability of hj becomes
0.
It is instructive to plug some specific values into the formula given by the
Falsification Theorem, to see what the convergence rate might look like. For
example, the theorem tells us that if we compare any pair of hypotheses
hi and hj on an
evidence stream cn that contains at least
m = 19 observations or experiments having δ ≥ .10 for the likelihood of
yielding a falsifying outcome, then the likelihood (on
hi·b·cn) of
obtaining an outcome sequence en that yields
likelihood-ratio P[en |
hj·b·cn]
/ P[en |
hi·b·cn]
= 0, will be at least as large as 1−(1−.1)19 = .865. (The reader is
invited to try other values of δ and m as well.)
A comment about the need for and usefulness of such
convergence theorems is in order, now that we’ve seen one. Given some specific
pair of scientific hypotheses hi and
hj one may directly compute the likelihood, given
(hi·b·cn),
that a proposed sequence of experiments or observations
cn will result in one of the sequences of outcomes
that yield low likelihood ratios. So, given a specific pair of hypotheses and a
proposed sequence of experiments, we don't need a general Convergence
Theorem to tell us the likelihood of obtaining refuting evidence. The
specific hypotheses hi and
hj tell us this themselves. They tell us
the likelihood of obtaining each specific outcome stream, including those that
refute the competitor or produce a very small likelihood ratio for it.
Furthermore, after we've actually performed an experiment and recorded its
outcome, all that matters is the actual ratio of likelihoods for that outcome.
Convergence theorems become moot.
The point of Likelihood Ratio Convergence Theorem (both the Falsification
Theorem and the part of the theorem still to come) is to assure us in
advance of the consideration of any specific pair of hypotheses that if the
possible evidence streams that test hypotheses have certain characteristics
which reflect the empirical distinctness of the hypotheses, then it is highly
likely that one of the sequences of outcomes will occur that yields a very small
likelihood ratio. These theorems provide relatively meager, but finite lower
bounds on how quickly such convergence is likely to be. Thus, they show that the
CoA is satisfied—in advance of our using the logic to test specific
hypotheses.
The Falsification Theorem shows what happens when the evidence stream
includes possible outcomes that may falsify the alternative hypothesis.
But what if no possibly falsifying outcomes are present? That is, what
if hypothesis hj only specifies various non-zero
likelihoods for possible outcomes? Or what if hj
does specify 0 likelihoods on some outcomes, but only those that
hi says are impossible, only those for which
hi also specifies 0 likelihoods? Such evidence
streams are undoubtedly much more common in practice than those containing
possibly falsifying outcomes. To cover evidence streams of this kind we first
need to identify a useful way to measure the degree to which hypotheses are
empirically distinct on such evidence.
Consider some particular sequence of outcomes en
that results from observations cn. The likelihood
ratio P[en |
hj·b·cn]
/ P[en |
hi·b·cn]
measures the extent to which the outcome sequence distinguishes between
hi and hj. But as a
measure of the power of evidence to distinguish among hypotheses, likelihood
ratios themselves provide a rather lopsided scale, a scale that ranges from 0 to
infinity with the midpoint, where en doesn't
distinguish at all between hi and
hj, at 1. So, rather than using raw likelihood
ratios to measure the ability of en to distinguish
between hypotheses, it proves more useful to employ a symmetric measure. The
logarithm of the likelihood ratio provides such a measure.
Definition: QI—the Quality of the
Information.
For each experiment or observation
ck, define the quality of the
information provided by oku for
distinguishing hj from
hi, given b, as follows:
QI[oku |
hi/hj |
b·ck] = log[P[oku |
hi·b·ck] /
P[oku |
hj·b·ck]].
Similarly, define QI[en |
hi/hj |
b·cn] = log[P[en |
hi·b·cn] /
P[en |
hj·b·cn]].
That is, QI is the base-2 logarithm of the ratio of the likelihood for
hi over that for
hj.
So, we measure the Quality of the Information an outcome would yield
in distinguishing between two hypotheses as the base-2 logarithm of the
likelihood ratio. This is clearly a measure of the outcome's evidential strength
at distinguishing between the two hypotheses.
By this measure, hypotheses hi and
hj assign the same likelihood value to a given
outcome oku just in case QI[oku |
hi/hj |
b·ck] = 0. QI measures information
on a logarithmic scale that is symmetric about the natural no-information
midpoint, 0. Positive information favors hi over
hj and negative information favors
hj over hi.
Relative to each hypothesis with background,
hi·b and
hj·b, it can be shown that the QI for a
sequence of outcomes is just the sum of the QIs of the individual outcomes in
the sequence:
| (15) |
QI[en |
hi/hj |
b·cn] |
= |
n
∑
k=1 |
QI[ek |
hi/hj |
b·ck]. |
Probability theorists measure the expected value of a quantity by
first multiplying each of its possible values by their probabilities of
occurring, and then summing these products. Thus, the expected value of
QI is given by the following formula:
Definition: EQI—the Expected Quality of the
Information.
Let's call hj
outcome-compatible with hi on evidence
stream ck just when for each possible
outcome sequence ek of
ck, if P[ek |
hi·b·ck]
> 0, then P[ek |
hj·b·ck]
> 0. We also adopt the convention that if P[oku |
hj·b·ck]
= 0, then the term QI[oku |
hi/hj |
b·ck] · P[oku |
hi·b·ck]
= 0, since the outcome oku has 0 probability of
occurring given
hi·b·ck.
For hj outcome-compatible with
hi on ck, define
EQI[ck |
hi/hj |
b] = ∑u
QI[oku |
hi/hj |
b·ck] · P[oku |
hi·b·ck].
Also, define EQI[cn |
hi/hj |
b] = ∑{en}
QI[en |
hi/hj |
b] · P[en |
hi·b·cn].
The EQI of an experiment or observation is the Expected Quality of its
Information for distinguishing hi from
hj when hi is true. It
is a measure of the expected evidential strength of the possible outcomes of an
experiment or observation at distinguishing between the hypotheses. Whereas QI
measures the ability of each particular outcome or sequence of outcomes to
empirically distinguish hypotheses, EQI measures the tendency of experiments or
observations to produce distinguishing outcomes. It can be shown that EQI tracks
empirical distinctness in a precise way. We return to this in a moment.
It is easily proved that the EQI for a sequence of observations
cn is just the sum of the EQIs of the individual
observations ck in the sequence:
| (16) |
EQI[cn |
hi/hj |
b] |
= |
n
∑
k=1 |
EQI[ck |
hi/hj |
b]. |
(For the proof, see the supplementary document Proof that the EQI for cn is the sum of
the EQI for the individual
ck.)
This suggests that it may be useful to average the values of the EQI[ck|
hi/hj |
b] over the number of observations n. We then obtain a measure
of the average expected quality of the information over the experiments
and observations that make up cn.
Definition: The Average Expected Quality of
Information
The average expected quality of information, EQI, from
cn for distinguishing
hj from hi, given
hi·b, is defined as:
| EQI[cn |
hi/hj |
b] |
= |
EQI[cn |
hi/hj |
b] ÷ n |
|
= |
| (1/n) |
n
∑
k=1 |
EQI[ck |
hi/hj
| b].
| |
It turns out that the value of EQI[ck |
hi/hj |
b] cannot be less than 0; and it will be greater just
in case hi is empirically distinct from
hj on at least one outcome
oku—i.e., just in case it is empirically
distinct in the sense that P[oku |
hi·b·ck]
≠ P[oku
|
hj·b·ck].
And the same goes for the average, EQI[cn |
hi/hj |
b].
Theorem: Nonnegativity of EQI.
EQI[ck |
hi/hj |
b] ≥ 0. And, EQI[ck |
hi/hj |
b] > 0 if and only if for at least one
of its possible outcomes oku, P[oku |
hi·b·ck]
≠ P[oku |
hj·b·ck].
As a result, EQI[cn |
hi/hj |
b] ≥ 0; and EQI[cn |
hi/hj |
b] > 0 if and only if at least one experiment or
observation ck has at least one possible outcome
oku such that P[oku |
hi·b·ck]
≠ P[oku |
hj·b·ck].
(For the proof, see the supplementary document The Effect on EQI of Partitioning the Outcome Space More Finely—and
Proof of the Nonnegativity of EQI Theorem.)
In fact, the finer one partitions the outcome space
Ok =
{ok1,…,okv,…,okw}
into a larger number of distinct outcomes with differing likelihood ratio
values, the larger EQI becomes.[20] This shows that EQI tracks empirical distinctness in
a precise way. The importance of the Non-negativity of EQI result for
the Likelihood Ratio Convergence Theorem will become apparent in a
moment.
We are now in a position to state the second part of the Likelihood Ratio
Convergence Theorem. It applies to all evidence streams not containing
possibly falsifying outcomes for hj when
hi holds—i.e., it applies to all evidence streams
for which hj is outcome-compatible with
hi on each ck in the
stream.
Likelihood Ratio Convergence Theorem 2—The Non-Falsifying
Refutation Theorem.
Suppose γ > 0 is a number smaller than
1/e2 (≈ .135; where ‘e’ is the base of the
natural logarithm). And suppose that for each possible outcome
oku of each observation condition
ck in cn, either
P[oku
|
hi·b·ck]
= 0 or P[oku |
hj·b·ck]
/ P[oku |
hi·b·ck]
≥ γ. Choose positive ε < 1, as small as you like, but large enough (for the
number of observations n being contemplated) that the value of EQI[cn |
hi/hj | b]
> −(log ε)/n. Then
P[{en :
P[en |
hj·b·cn]/
P[en |
hi·b·cn]
< ε} |
hi·b·cn]
>
| 1 |
− |
1
—
n |
· |
(log γ)2
————————————
(EQI[cn
| hi/hj |
b] + (log ε)/n
)2 |
(For proof see the supplementary document Proof of the Non-Falsifying Refutation Theorem.)
This theorem provides reasonable sufficient conditions for the
likely refutation of false alternatives via exceeding small
likelihood ratios. The conditions under which this happens characterize the
degree to which the hypotheses involved are empirically distinct from each
other. The theorem says that when these conditions are met, hypothesis
hi (together with
b·cn) makes the likelihood at
least within (1/n) · (log γ)2 / (EQI[cn |
hi/hj | b] +
(log ε)/n)2 of 1 that an outcome sequence
en will occur that yields a likelihood ratio
smaller than chosen ε. It turns out that in almost every case the actual
likelihood of obtaining such evidence will be much closer to 1 than
this factor indicates.[21] Thus, the theorem provides a lower bound on the
likelihood of obtaining small likelihood ratios. It shows that the larger the
value of EQI for an evidence
stream, the more likely that stream is to produce a sequence of outcomes that
yield very small likelihood ratios. But even if EQI remains quite small, a long enough
stream, n, will almost surely produce an outcome sequence having a very
small likelihood ratio.[22]
Notice that the antecedent condition of the theorem, that “either P[oku |
hi·b·ck]
= 0 or P[oku |
hj·b·ck]
/ P[oku
|
hi·b·ck]
≥ γ, for some γ > 0 but less than 1/e2 (≈ .135)”, does
not favor hypothesis hi in any way. The condition
only rules out the possibility that some outcomes might furnish extremely
strong evidence against hj relative
to hi. This condition is only needed because our
measure of evidential distinguishability, QI, blows up when the ratio P[oku |
hj·b·ck]
/ P[oku
|
hi·b·ck]
is extremely small. Furthermore, this condition is really no restriction at all
on possible experiments or observations. If ck has
some possible outcome sentence oku that would make
P[oku |
hj·b·ck]
/ P[oku
|
hi·b·ck]
< γ (for a given small γ of interest), one may disjunctively lump
oku together with some other outcome sentence
okv for ck. Then, the
antecedent condition of the theorem will be satisfied, but with the sentence
‘(oku okv)’ treated
as a single outcome (e.g., in the formula for EQI). It can be proved that the
only effect of such “disjunctive lumping” is to make EQI a bit smaller than it
would otherwise be. If the too refuting disjunct
oku actually occurs when the evidence is collected,
all the better. We merely failed to take this possibility into account in
computing our lower bound on the likelihood that refutation via likelihood
ratios will occur.
The point of the two Convergence Theorems explored in this section
is to assure us, in advance of the consideration of any specific pair of
hypotheses, that if the possible evidence streams that test them have certain
characteristics which reflect their evidential distinguishability, it is highly
likely that outcomes yielding small likelihood ratios will result. And these
theorems provide finite lower bounds on how quickly convergence is likely to
occur, bounds that show one need not wait for convergence through some
infinitely long run. Indeed, for any evidence sequence in which the probability
distributions are at all well behaved, the actual likelihood of
obtaining outcomes that yield small likelihood ratio values will inevitably be
much higher than the lower bounds given by Theorems 1 and 2.
In sum, according to Theorems 1 and 2, each hypothesis
hi says, via likelihoods, that given enough
observations, it is very likely to dominate its empirically distinct
rivals in a contest of likelihood ratios. And even a sequence of observations
with an extremely low average expected quality of information is very
likely to do the job if that sequence is long enough. Presumably, the true
hypothesis speaks truthfully about this, and its competitors lie. Thus (by
Equation 9), as evidence accumulates, the degree of support for false
hypotheses will very probably approach 0, indicating that they are probably
false; and as this happens, (by Equations 10 and 11) the degree of support for
the true hypothesis will approach 1, indicating its probable truth. The
Criterion of Adequacy (CoA) is satisfied.
Up to this point we have been supposing that likelihoods possess objective or
agreed numerical values. Although this supposition is often satisfied in
scientific contexts, there are important settings where it is unrealistic—where
individual agents have only vague likelihood values, and where the community
cannot agree on precise values.[23] Let us now see how the supposition of precise, agreed
likelihood values may be relaxed in a reasonable way.
Recall why agreement or near agreement on precise values for likelihoods is
highly desirable. To the extent that members of a scientific community disagree
on the likelihoods, they disagree about the empirical content of their
hypotheses, about what each hypothesis says about how the world is
likely to be. This can lead to disagreement about which hypotheses are refuted
or favored by a given stream of evidence. Similarly, to the extent that the
values of likelihoods are vague for an individual agent, he or she may be unable
to determine which of several hypotheses is refuted or favored by a given
evidence stream.
Notice, however, that the values of individual likelihoods are not what is
most crucial to the way evidence impacts hypotheses. Rather (as Equations 9-11
show), it is ratios of likelihoods that do the heavy lifting. So, even
if two support functions Pα and Pβ
disagree on the values of likelihoods, they may, nevertheless, largely agree on
the refutation or support that accrues to various rival hypotheses when the
following condition is satisfied:
Directional Agreement Condition:
The
likelihood ratios due to each of a pair of support functions
Pα and Pβ will be said to agree in
direction (with respect to the possible outcomes of experiments or
observations relevant to a pair of hypotheses) just in case
- whenever possible outcome sequence en makes
Pα[en
|
hj·b·cn]
/ Pα[en |
hi·b·cn]
< 1, it makes Pβ[en
|
hj·b·cn]
/ Pβ[en |
hi·b·cn]
< 1 as well;
- whenever possible outcome sequence en makes
Pα[en
|
hj·b·cn]
/ Pα[en |
hi·b·cn]
> 1, it makes Pβ[en
|
hj·b·cn]
/ Pβ[en |
hi·b·cn]
> 1 as well;
- each of these likelihood ratios is either extremely close to 1 for
neither support function or for both support functions.[24]
When this condition holds, the evidence will support
hi over hj according
to Pα just in case it does so for Pβ as
well, although the strength of support may differ. The rate at which
the likelihood ratios increase or decrease on a stream of evidence may differ
for the two support functions, but the impact of the cumulative evidence should
ultimately affect their refutation or support in much the same way.
When likelihoods are vague or diverse, we may take the approach we employed
for vague and diverse prior plausibility assessments. We may
extend the vagueness sets for individual agents to include a range of
inductive support functions, each within the range of values for the likelihoods
and the prior probabilities that the agent finds acceptable. Similarly, we may
extend the Diversity sets for communities of agents to include support
functions for the range of likelihoods and prior probabilities (from the
vagueness sets) of all members of the community. This will make no
trouble for the convergence to agreement on the empirical support for
hypotheses provided that the Directional Agreement Condition
is satisfied by all support functions in the extended vagueness or
Diversity sets of agents.
As it happens, the Likelihood Ratio Convergence Theorem can
also do useful work here. The proof of the theorem doesn't actually depend on
the assumption that likelihoods are objective or have intersubjectively agreed
values. It can be shown to apply to each inductive support function
Pα individually. The only problem with applying this result
across a range of support functions is that if their likelihoods differ, then
Pα may disagree with Pβ on which of the
hypotheses is favored by a given sequence of evidence. An evidence stream that
favors hi according to Pα may
instead favor hj according to
Pβ. However, when the Directional Agreement
Condition holds for a given collection of these functions, this cannot
happen. Directional Agreement means that the empirical import of
hypotheses is considered similar enough by Pα and
Pβ that a sequence of outcomes may favor a hypothesis
according to Pα only if it does so for
Pβ as well.
Thus, when the Directional Agreement Condition holds, if enough
empirically distinguishing experiments or observations can be performed, all
support functions in an extended vagueness or diversity set
will very probably come to agree that the likelihood ratios for empirically
distinct false competitors of a true hypothesis are extremely small. As that
happens, the community comes to agree on the refutation of these competitors,
and the true hypothesis rises to the top of the heap.[25]
What if the true hypothesis has empirically equivalent rivals? Their
posterior probabilities must rise as well. We may only be assured that the
disjunction of the true hypothesis with its empirically equivalent rivals will
be driven to 1 as evidence lays low its empirically distinct rivals. The true
hypothesis may itself approach 1 only if either it has no empirically equivalent
rivals, or whatever equivalent rivals it has are laid low as well by
non-evidential plausibility considerations.
- Boole, G., 1854. The Laws of Thought, London: MacMillan.
Republished in 1958 by Dover: New York.
- Carnap, R., 1950. Logical Foundations of Probability, Chicago:
University of Chicago Press.
- -----, 1952. The Continuum of Inductive Methods, Chicago:
University of Chicago Press.
- -----, 1963. “Replies and Systematic Expositions”, in The Philosophy
of Rudolf Carnap, P. A. Schilpp, (ed.), Open Court, Illinois: La Salle.
- De Finetti, B., 1937. “La Prévision: Ses Lois Logiques, Ses Sources
Subjectives”, Annales de l’Institut Henri Poincaré, 7, 1-68;
translated as “Foresight. Its Logical Laws, Its Subjective Sources”, in
Studies in Subjective Probability, H. E. Kyburg, Jr. and H. E.
Smokler (eds.), Robert E. Krieger Publishing Company, 1980.
- Dubois, D., Prade, H., 1980. Fuzzy Sets and Systems, New York:
Academic Press.
- -----, 1990. "An Introduction to Possibilistic and Fuzzy Logics". In G.
Shafer and J. Pearl, editors, Readings in Uncertain Reasoning,
742-761. Morgan Kaufmann.
- Duhem, P., 1906. La theorie physique. Son objet et sa structure,
Paris: Chevalier et Riviere; translated by P.P. Wiener, The Aim and
Structure of Physical Theory, Princeton, NJ: Princeton
University
Press, 1954.
- Chihara, C., 1987. “Some Problems for Bayesian Confirmation Theory”,
British Journal for the Philosophy of Science 38, 551-560.
- Christensen, D. 1999. “Measuring Evidence”, Journal of Philosophy
96, 437-61.
- Earman, J. 1992. Bayes or Bust? Cambridge, MA: MIT Press.
- Edwards, A.W.F. 1972. Likelihood. Cambridge: Cambridge University
Press.
- Edwards, W., Lindman, H., and Savage, L. J., 1963. “Bayesian Statistical
Inference for Psychological Research”, Psychological Review 70,
193-242.
- Eells, E., 1985. “Problems of Old Evidence”, Pacific Philosophical
Quarterly, 66, 283-302.
- Eells, E., Fitelson, B., 2000. “Measuring Confirmation and Evidence”,
The Journal of Philosophy 97, 663-672.
- Field, H., 1977. “Logic, Meaning, and Conceptual Role”, Journal of
Philosophy, 74, 379-409.
- Fisher, R.A., 1922. “On the Mathematical Foundations of Theoretical
Statistics”, Philosophical Transactions of the Royal Society, series A,
309-368.
- Fitelson, B., 1999. “The Plurality of Bayesian Measures of Confirmation
and the Problem of Measure Sensitivity”, Philosophy of Science 66,
S362-378.
- Friedman, N. , Halpern, J.Y., 1995. “Plausibility Measures: A User's
Guide”. In Proc. UAI 95, 175-184.
- Glymour, Clark. 1980. Theory and Evidence. Princeton: Princeton
University Press.
- Hacking, Ian. 1965. Logic of Statistical Inference. Cambridge:
Cambridge University Press.
- Hájek, A., 2003. “What Conditional Probability Could Not Be”,
Synthese 137, 273–323.
- -----, 2003. “Interpretations of the Probability Calculus”, in the
Stanford Encyclopedia of Philosophy, (Summer 2003 Edition), Edward N.
Zalta (ed.), URL =
http://plato.stanford.edu/archives/sum2003/entries/probability-interpret/
- Halpern, J. Y. 2003. Reasoning About Uncertainty. Cambridge, MA:
MIT Press.
- Harper, W. 1976. “Rational Belief Change, Popper Functions and
Counterfactuals”, in W. Harper and C. Hooker, eds., Foundations of
Probability Theory, Statistical Inference, and Statistical Theories of
Science, vol. I. Dordrecht: Reidel, 73-115.
- Hawthorne, J., 1993. “Bayesian Induction Is Eliminative
Induction”, Philosophical Topics, 21, 99-138.
- -----, 1994.“On the Nature of Bayesian Convergence”, PSA 1994, v.
1, 1994; pp. 241-249.
- Hawthorne, J., Bovens, Luc, 1999. “The Preface, the Lottery, and the Logic
of Belief”, Mind, 108, 241-264.
- Horwich, P., 1982. Probability and Evidence. Cambridge: Cambridge
University Press.
- Howson, C., Urbach, P., 1993. Scientific Reasoning: The Bayesian
Approach, 2nd edition. Chicago: Open Court.
- Jaynes, E. T., 1968. “Prior Probabilities”, I.E.E.E. Transactions on
Systems Science and Cybernetics, SSC-4, 227-241.
- Jeffrey, R. C., 1983. The Logic of Decision, 2nd
edition. Chicago: University of Chicago Press.
- -----, 1987. “Alias Smith and Jones: The Testimony of the Senses”,
Erkenntnis 26, 391-399.
- -----, 1992. Probability and the Art of Judgment. New York:
Cambridge University Press.
- Jeffreys, H., 1939. Theory of Probability. Oxford University
Press.
- Joyce, J., 1998. “A Nonpragmatic Vindication of Probabilism”,
Philosophy of Science, 65 (4) 575-603.
- -----, 1999. The Foundations of Causal Decision Theory. New York:
Cambridge University Press.
- -----, 2003. “Bayes' Theorem”,
in the Stanford Encyclopedia of Philosophy, (Summer 2003 Edition),
Edward N. Zalta (ed.), URL =
http://plato.stanford.edu/archives/win2003/entries/bayes-theorem/
- Keynes, J. M., 1921. A Treatise on Probability. Macmillan and Co.
- Koopman, B., 1940. “The Bases of Probability”, Bulletin of the
American Mathematical Society, 46, 763-774. Reprinted in Kyburg, H., and
Smokler, H. (eds.), 1980, Studies in Subjective Probability, 2nd ed.
Huntington, N.Y.: Krieger Publ. Co.
- Kyburg, H., 1974. The Logical Foundations of Statistical
Inference. Dordrecht: Reidel.
- ----- (1977). “Randomness and the Right Reference Class”, Journal of
Philosophy, 74: 501-520.
- Lange, M., 1999. “Calibration and the Epistemological Role of Bayesian
Conditionalization”, Journal of Philosophy 96, 294-324.
- Levi, I., 1967. Gambling with Truth. New York: Knopf.
- -----, 1977. “Direct Inference,” Journal of Philosophy, 74, 5-29.
- -----, 1978. “Confirmational Conditionalization”, Journal of
Philosophy, 75, 730-737.
- ----- 1980. The Enterprise of Knowledge. Cambridge, Mass.: MIT
Press.
- Lewis, David, 1980. “A Subjectivist's Guide to Objective Chance”, in
Richard C. Jeffrey, ed., Studies in Inductive Logic and Probability, vol.
2. Berkeley: University of California Press, 263-293.
- Maher, P., 1996. “Subjective and Objective Confirmation”, Philosophy
of Science 63, 149-174.
- McGee, V., 1994. “Learning the Impossible”, in E. Eells and B. Skyrms,
eds., Probability and Conditionals. New York: Cambridge University
Press, 179-200.
- Popper, K., 1968. The Logic of Scientific Discovery,
3rd edition, London: Hutchinson; 1968.
- Quine, W.V. 1953. “Two Dogmas of Empiricism”, in From a Logical Point
of View, New York: Harper Torchbooks.
Routledge Encyclopedia of
Philosophy, Version 1.0, London: Routledge
- Ramsey, F. P., 1926. “Truth and Probability”, in Foundations of
Mathematics and other Essays, R. B. Braithwaite (ed.), Routledge & P.
Kegan,1931, 156-198; reprinted in Studies in Subjective Probability,
H. E. Kyburg, Jr. and H. E. Smokler (eds.), 2nd ed., R. E. Krieger
Publishing Company, 1980, 23-52; reprinted in Philosophical Papers,
D. H. Mellor (ed.) Cambridge: University Press, Cambridge, 1990.
- Renyi, A., 1970. Foundations of Probability, Holden-Day, Inc.
- Rosenkrantz, R.D., 1981. Foundations and Applications of Inductive
Probability. Atascadero, CA: Ridgeview Publishing.
- Royall, R. 1997. Statistical Evidence: A Likelihood Paradigm. New
York: Chapman & Hall/CRC.
- Salmon, W., 1966. The Foundations of Scientific Inference.
University of Pittsburgh Press.
- Savage, L. J., 1954. The Foundations of Statistics, John Wiley
(2nd ed., New York: Dover 1972).
- Savage, L.J., et al.1962. The Foundations of Statistical
Inference. London: Methuen.
- Shafer, G. 1976. A Mathematical Theory of Evidence. Princeton
Univ. Press.: Princeton, NJ.
- -----, 1990. “Perspectives on the Theory and Practice of Belief
Functions”, International Journal of Approximate Reasoning, 3, 1-40.
- Skyrms, B., 1984. Pragmatics and Empiricism. New Haven: Yale
University Press.
- -----, 1990. The Dynamics of Rational Deliberation. Cambridge,
Mass.: Harvard University Press.
- -----, 2000. Choice and Chance, 4th edition.
Wadsworth, Inc.
- Sober, E., 2002. “Bayesianism − its Scope and Limits”, in Swinburne
(2002), 21-38.
- Spohn, W., 1988. “Ordinal Conditional Functions: A Dynamic Theory of
Epistemic States.” In W. Harper and B. Skyrms, editors, Causation in
Decision, Belief Change, and Statistics, vol. 2, 105-134. Dordrecht:
Reidel.
- Swinburne, R. 2002. Bayes's Theorem. Oxford: Oxford University
Press.
- Talbot, W., 2001. “Bayesian Epistemology”, in the Stanford Encyclopedia of
Philosophy (Fall 2001 Edition), Edward N. Zalta (ed.), URL =
http://plato.stanford.edu/archives/fall2001/entries/epistemology-bayesian/
- Teller, P., 1976. “Conditionalization, Observation, and Change of
Preference”, in W. Harper and C.A. Hooker, eds., Foundations of
Probability Theory, Statistical Inference, and Statistical Theories of
Science. Dordrecht: D. Reidel.
- Van Fraassen, B. C., 1983. “Calibration: A Frequency Justification for
Personal Probability ”, in R.S. Cohen and L. Laudan, eds., Physics,
Philosophy, and Psychoanalysis: Essays in Honor of Adolf Grunbaum.
Dordrecht: Reidel.
- Venn, J., 1876. The Logic of Chance, 2nd ed.,
Macmillan and co; reprinted, New York, 1962.
- Zadeh, L. 1965. “Fuzzy Sets”, Information and Control, 8:
338-353.
- -----, 1978. “Fuzzy Sets as a Basis for a Theory of Possibility”,
Fuzzy Sets and Systems, vol. 1, 3-28.
- Probability and Induction, Course Syllabus with Links,
Branden Fitelson (Philosophy, UC/Berkeley). The syllabus is a great
resource—it contains links to online copies of a number of important articles
on the central issues, listed by topic.
- Miscellany of
Works on Probabilistic Thinking, A collection of on-line articles on
Subjective Probability and probabilistic reasoning by Richard Jeffrey and by
several other philosophers writing on related issues.
- Teaching
Theory of Knowledge: Probability and Induction, A very extensive outline
of issues in Probability and Induction, each topic accompanied by a list of
relevant books and articles (without links), compiled by Brad Armendt
(Philosophy, Arizona State University) and Martin Curd (Philosophy, Purdue
University).
- Sherlock Holmes and Probabilistic Induction, by Soshichi
Uchii (Philosophy and History of Science, University of Kyoto)
- Inductive Logic, (in
PDF), by Branden Fitelson, forthcoming in Philosophy of Science: An
Encyclopedia, (J. Pfeifer and S. Sarkar, eds.), Routledge. An extensive
encyclopedia article on inductive logic.
- Bayesian Network Without Tears, (in PDF), by Eugene Charniak
(Computer Science and Cognitive Science, Brown University). An introductory
article on Bayesian inference.
Bayes' Theorem | epistemology:
Bayesian | probability,
interpretations of
Acknowledgements
Thanks to James Joyce and Ed Zalta for many valuable
comments and suggestions.
A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z
Stanford Encyclopedia of Philosophy