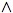 Q, the meet
of P and Q in L(H); also in this
case their join is given by P
Q, the meet
of P and Q in L(H); also in this
case their join is given by P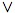 Q =
P+Q − PQ.
Q =
P+Q − PQ.version history
|
Stanford Encyclopedia of PhilosophyA | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z
|
last substantive content
change
|
| The Encyclopedia Now Needs
Your Support Please Read How You Can Help Keep the Encyclopedia Free |
At its core, quantum mechanics can be regarded as a non-classical probability calculus resting upon a non-classical propositional logic. More specifically, in quantum mechanics each probability-bearing proposition of the form "the value of physical quantity A lies in the range B" is represented by a projection operator on a Hilbert space H. These form a non-Boolean -- in particular, non-distributive -- orthocomplemented lattice. Quantum-mechanical states correspond exactly to probability measures (suitably defined) on this lattice.
What are we to make of this? Some have argued that the empirical success of quantum mechanics calls for a revolution in logic itself. This view is associated with the demand for a realistic interpretation of quantum mechanics, i.e., one not grounded in any primitive notion of measurement. Against this, there is a long tradition of interpreting quantum mechanics operationally, that is, as being precisely a theory of measurement. On this latter view, it is not surprising that a "logic" of measurement-outcomes, in a setting where not all measurements are compatible, should prove not to be Boolean. Rather, the mystery is why it should have the particular non-Boolean structure that it does in quantum mechanics. A substantial literature has grown up around the programme of giving some independent motivation for this structure -- ideally, by deriving it from more primitive and plausible axioms governing a generalized probability theory.
It is uncontroversial (though remarkable) that the formal apparatus of quantum mechanics reduces neatly to a generalization of classical probability in which the role played by a Boolean algebra of events in the latter is taken over by the "quantum logic" of projection operators on a Hilbert space.[1] Moreover, the usual statistical interpretation of quantum mechanics asks us to take this generalized quantum probability theory quite literally -- that is, not as merely a formal analogue of its classical counterpart, but as a genuine doctrine of chances. In this section, I survey this quantum probability theory and its supporting quantum logic.[2]
[For further background on Hilbert spaces, see Supplement 1: The Basic Theory of Hilbert Spaces. For further background on ordered sets and lattices, see Supplement 2: The Basic Theory of Ordering Relations. Concepts and results explained these supplements will be used freely in what follows.]
The quantum-probabilistic formalism, as developed by von Neumann [1932], assumes that each physical system is associated with a (separable) Hilbert space H, the unit vectors of which correspond to possible physical states of the system. Each "observable" real-valued random quantity is represented by a self-adjoint operator A on H, the spectrum of which is the set of possible values of A. If u is a unit vector in the domain of A, representing a state, then the expected value of the observable represented by A in this state is given by the inner product <Au,u>. The observables represented by two operators A and B are commensurable iff A and B commute, i.e., AB = BA. (For further discussion, see the entry on Quantum Mechanics.)
the relation between the properties of a physical system on the one hand, and the projections on the other, makes possible a sort of logical calculus with these. However, in contrast to the concepts of ordinary logic, this system is extended by the concept of "simultaneous decidability" which is characteristic for quantum mechanics [1932, p. 253].
Let's examine this "logical calculus" of projections. Ordered by set-inclusion, the closed subspaces of H form a complete lattice, in which the meet (greatest lower bound) of a set of subspaces is their intersection, while their join (least upper bound) is the closed span of their union. Since a typical closed subspace has infinitely many complementary closed subspaces, this lattice is not distributive; however, it is orthocomplemented by the mapping
M → M⊥ = {v∈H | ∀u∈M(<v,u> = 0)}.
In view of the above-mentioned one-one correspondence between closed
subspaces and projections, we may impose upon the set
L(H) the structure of a complete orthocomplemented
lattice, defining P≤Q, where ran(P) ⊆
ran(Q) and P′ = 1 − P (so
that ran(P′) = ran(P)⊥). It is
straightforward that P≤Q just in case PQ = QP = P.
More generally, if PQ = QP, then PQ = PQ, the meet
of P and Q in L(H); also in this
case their join is given by PQ =
P+Q − PQ.
1.1 Lemma:
Let P and Q be projection operators on the Hilbert space H. The following are equivalent:
- PQ = QP
- The sublattice of L(H) generated by P, Q, P′ and Q′ is Boolean
- P, Q lie in a common Boolean sub-ortholattice of L(H).
Adhering to the idea that commuting observables -- in particular, projections -- are simultaneously measurable, we conclude that the members of a Boolean "block" (that is, a Boolean sub-ortholattice) of L(H) are simultaneously testable. This suggests that we can maintain a classical logical interpretation of the meet, join and orthocomplement as applied to commuting projections.
The foregoing discussion motivates the following. Call projections P and Q orthogonal, and write P⊥Q iff P ≤ Q′. Note that P⊥Q iff PQ = QP = 0. If P and Q are orthogonal projections, then their join is simply their sum; traditionally, this is denoted P⊕Q. We denote the identity mapping on H by 1.
1.2 Definition:
A (countably additive) probability measure on L(H) is a mapping μ : L → [0,1] such that μ(1) = 1 and, for any sequence of pair-wise orthogonal projections Pi, i = 1,2,...μ(⊕i Pi) = ∑i μ(Pi)
Here is one way in which we can manufacture a probability measure on L(H). Let u be a unit vector of H, and set μu(P) = <Pu,u>. This gives the usual quantum-mechanical recipe for the probability that P will have value 1 in the state u. Note that we can also express μu as μu(P) = Tr(P Pu), where Pu is the one-dimensional projection associated with the unit vector u.
More generally, if μi, i=1,2, , are probability measures on L(H), then so is any "mixture", or convex combination μ = Σi tiμi where 0≤ti≤1 and Σi ti = 1. Given any sequence u1, u2, , of unit vectors, let μi = μui and let Pi = Pui. Forming the operator
W = t1P1 + t2P2 + ,one sees that
μ(P) = t1Tr(P P1) + t2Tr(P P2) + ... = Tr(WP)
An operator expressible in this way as a convex combination of one-dimensional projections in is called a density operator. Thus, every density operator W gives rise to a countably additive probability measure on L(H). The following striking converse, due to A. Gleason [1957], shows that the theory of probability measures on L(H) is co-extensive with the theory of (mixed) quantum mechanical states on H:
1.3 Gleason's Theorem:
Let H have dimension > 2. Then every countably additive probability measure on L(H) has the form μ(P) = Tr(WP), for a density operator W on H.
An important consequence of Gleason's Theorem is that L(H) does not admit any probability measures having only the values 0 and 1. To see this, note that for any density operator W, the mapping u → <Wu,u> is continuous on the unit sphere of H. But since the latter is connected, no continuous function on it can take only the two values 0 and 1. This result is often taken to rule out the possibility of hidden variables -- an issue taken up in more detail in section 6.
From the single premise that the "experimental propositions" associated with a physical system are encoded by projections in the way indicated above, one can reconstruct the rest of the formal apparatus of quantum mechanics. The first step, of course, is Gleason's theorem, which tells us that probability measures on L(H) correspond to density operators. There remains to recover, e.g., the representation of "observables" by self-adjoint operators, and the dynamics (unitary evolution). The former can be recovered with the help of the Spectral theorem and the latter with the aid of a deep theorem of E. Wigner on the projective representation of groups. See also R. Wright [1980]. A detailed outline of this reconstruction (which involves some distinctly non-trivial mathematics) can be found in the book of Varadarajan [1985]. The point to bear in mind is that, once the quantum-logical skeleton L(H) is in place, the remaining statistical and dynamical apparatus of quantum mechanics is essentially fixed. In this sense, then, quantum mechanics -- or, at any rate, its mathematical framework -- reduces to quantum logic and its attendant probability theory.
The reduction of QM to probability theory based on L(H) is mathematically compelling, but what does it tell us about QM --- or, assuming QM to be a correct and complete physical theory, about the world? How, in other words, are we to interpret the quantum logic L(H)? The answer will turn on how we unpack the phrase, freely used above,
(*) The value of the observable A lies in the range B.
One possible reading of (*) is operational: "measurement of the observable A would yield (or will yield, or has yielded) a value in the set B ". On this view, projections represent statements about the possible results of measurements. This sits badly with realists of a certain stripe, who, shunning reference to measurement, prefer to understand (*) as a property ascription: "the system has a certain categorical property, which corresponds to the observable A having, independently of any measurement, a value in the set B". (One must be careful in how one understands this last phrase, however: construed incautiously, it seems to posit a hidden-variables interpretation of quantum mechanics of just the sort ruled out by Gleason's Theorem. I will have more to say about this below.)
The interpretation of projection operators as representing the properties of a physical system is already explicit in von Neumann's Grundlagen.. However, the logical operations discussed there apply only to commuting projections, which are identified with simultaneously decidable propositions. In [1936] von Neumann and Birkhoff took a step further, proposing to interpret the lattice-theoretic meet and join of projections as their conjunction and disjunction, whether or not they commute. Immediately this proposal faces the problem that the lattice L(H) is not distributive, making it impossible to give these quantum connectives a truth-functional interpretation. Undaunted, von Neumann and Birkhoff suggested that the empirical success of quantum mechanics as a framework for physics casts into doubt the universal validity of the distributive laws of propositional logic. Their phrasing remains cautious:
Whereas logicians have usually assumed that properties of negation were the ones least able to withstand a critical analysis, the study of mechanics points to the distributive identities as the weakest link in the algebra of logic. [1937, p. 839]
In the 1960s and early 1970s, this thesis was advanced rather more aggressively by a number of authors, including especially David Finkelstein and Hilary Putnam, who argued that quantum mechanics requires a revolution in our understanding of logic per se. According to Putnam [1968], Logic is as empirical as geometry. We live in a world with a non-classical logic.
For Putnam, the elements of L(H) represent categorical properties that an object possesses, or does not, independently of whether or not we look. Inasmuch as this picture of physical properties is confirmed by the empirical success of quantum mechanics, we must, on this view, accept that the way in which physical properties actually hang together is not Boolean. Since logic is, for Putnam, very much the study of how physical properties actually hang together, he concludes that classical logic is simply mistaken: the distributive law is not universally valid.
Classically, if S is the set of states of a physical system, then every subset of S corresponds to a categorical property of the system, and vice versa. In quantum mechanics, the state space is the (projective) unit sphere S = S(H) of a Hilbert space. However, not all subsets of S correspond to quantum-mechanical properties of the system. The latter correspond only to subsets of the special form S ∩ M, for M a closed linear subspace of H. In particular, only subsets of this form are assigned probabilities. This leaves us with two options. One is to take only these special properties as real (or physical, or meaningful), regarding more general subsets of S as corresponding to no real categorical properties at all. The other is to regard the quantum properties as a small subset of the set of all physically (or at any rate, metaphysically) reasonable, but not necessarily observable, properties of the system. On this latter view, the set of all properties of a physical system is entirely classical in its logical structure, but we decline to assign probabilities to the non-observable properties.[3]
This second position, while certainly not inconsistent with realism per se, turns upon a distinction involving a notion of "observation", "measurement", "test", or something of this sort -- a notion that realists are often at pains to avoid in connection with fundamental physical theory. Of course, any realist account of a statistical physical theory such as quantum mechanics will ultimately have to render up some explanation of how measurements are supposed to take place. That is, it will have to give an account of which physical interactions between "object" and "probe" systems count as measurements, and of how these interactions cause the probe system to evolve into final outcome-states that correspond to -- and have the same probabilities as -- the outcomes predicted by the theory. This is the notorious measurement problem.
In fact, Putnam advanced his version of quantum-logical realism as offering a (radical) dissolution of the measurement problem: According to Putnam, the measurement problem (and indeed every other quantum-mechanical "paradox") arises through an improper application of the distributive law, and hence disappears once this is recognized. This proposal, however, is widely regarded as mistaken.
As mentioned above, realist interpretations of quantum mechanics must be careful in how they construe the phrase "the observable A has a value in the set B". The simplest and most traditional proposal -- often dubbed the "eigenstate-eigenvalue link" (Fine 1973) -- is that (*) holds if and only if a measurement of A yields a value in the set B with certainty, i.e., with (quantum-mechanical!) probability 1. While this certainly gives a realist interpretation of (*)[4], it does not provide a solution to the measurement problem. Indeed, we can use it to give a sharp formulation of that problem: even though A is certain to yield a value in B when measured, unless the quantum state is an eigenstate of the measured observable A, the system does not possess any categorical property corresponding to A's having a specific value in the set B. Putnam seems to assume that a realist interpretation of (*) should consist in assigning to A some unknown value within B, for which quantum mechanics yields a non-trivial probability. However, an attempt to make such assignments simultaneously for all observables runs afoul of Gleason's Theorem.[5]
If we put aside scruples about measurement as a primitive term in physical theory, and accept a principled distinction between testable and non-testable properties, then the fact that L(H) is not Boolean is unremarkable, and carries no implication about logic per se. Quantum mechanics is, on this view, a theory about the possible statistical distributions of outcomes of certain measurements, and its non-classical logic simply reflects the fact that not all observable phenomena can be observed simultaneously. Because of this, the set of probability-bearing events (or propositions) is less rich than it would be in classical probability theory, and the set of possible statistical distributions, accordingly, less tightly constrained. That some non-classical probability distributions allowed by this theory are actually manifested in nature is perhaps surprising, but in no way requires any deep shift in our understanding of logic or, for that matter, of probability.
This is hardly the last word, however. Having accepted all of the above, there still remains the question of why the logic of measurement outcomes should have the very special form L(H), and never anything more general.[6] This question entertains the idea that the formal structure of quantum mechanics may be uniquely determined by a small number of reasonable assumptions, together perhaps with certain manifest regularities in the observed phenomena. This possibility is already contemplated in von Neumann's Grundlagen (and also his later work in continuous geometry), but first becomes explicit -- and programmatic -- in the work of George Mackey [1957, 1963]. Mackey presents a sequence of six axioms, framing a very conservative generalized probability theory, that underwrite the construction of a logic of experimental propositions, or, in his terminology, questions, having the structure of a sigma-orthomodular poset. The outstanding problem, for Mackey, was to explain why this poset ought to be isomorphic to L(H):
Almost all modern quantum mechanics is based implicitly or explicitly on the following assumption, which we shall state as an axiom:Axiom VII: The partially ordered set of all questions in quantum mechanics is isomorphic to the partially ordered set of all closed subspaces of a separable, infinite dimensional Hilbert space.This axiom has rather a different character from Axioms I through VI. These all had some degree of physical naturalness and plausibility. Axiom VII seems entirely ad hoc. Why do we make it? Can we justify making it? Ideally, one would like to have a list of physically plausible assumptions from which one could deduce Axiom VII. Short of this one would like a list from which one could deduce a set of possibilities for the structure all but one of which could be shown to be inconsistent with suitably planned experiments. [19, pp. 71-72]
Since Mackey's writing there has grown up an extensive technical literature exploring variations on his axiomatic framework in an effort to supply the missing assumptions. The remainder of this article presents a brief survey of the current state of this project.
Rather than restate Mackey's axioms verbatim, I shall paraphrase them in the context of an approach to generalized probability theory due to D. J. Foulis and C. H. Randall having -- among the many more or less homologous approaches available[7] -- certain advantages of simplicity and flexibility. References for this section are [Foulis, Greechie and Rüttimann 1992, Foulis, Piron and Randall 1983, Foulis and Randall 1982, Randall and Foulis 1983; see also Gudder 1985 and Wilce 2000b for surveys.]
It will be helpful to begin with a review of classical probability theory. In its simplest formulation, classical probability theory deals with a (discrete) set E of mutually exclusive outcomes, as of some measurement, experiment, etc., and with the various probability weights that can be defined thereon --- that is, with mappings ω : E → [0,1] summing to 1 over E.[8]
Notice that the set Δ(E) of all probability weights on E is convex, in that, given any sequence ω1,ω2, of probability weights and any sequence t1,t2, of non-negative real numbers summing to one, the convex sum or mixture t1ω1 + t2ω2 + (taken pointwise on E) is again a probability weight. The extreme points of this convex set are exactly the "point-masses" δ(x) associated with the outcomes x ∈ E:
δ(x)(y) = 1 if x = y, and 0 otherwise.
Thus, Δ(E) is a simplex: each point ω∈Δ(E) is representable in a unique way as a convex combination of extreme points, namely:
ω = ∑ω(x)δ(x)
We need also to recall the concept of a random variable. If E is an outcome set and V, some set of values (real numbers, pointer-readings, or what not), a V-valued random variable is simply a mapping f : E → V. The heuristic (but it need only be taken as that) is that one measures the random variable f by performing the experiment represented by E and, upon obtaining the outcome x ∈ E, recording f(x) as the measured value. Note that if V is a set of real numbers, or, more generally, a subset of a vector space, we may define the expected value of f in a state ω ∈ Δ(E) by:
E(f,ω) = ∑x∈E f(x)ω(x).
 is called a
test. The set X = ∪ of all outcomes of
all tests belonging to is called the
outcome space of . Notice that we allow
distinct tests to overlap, i.e., to have outcomes in common.[9]
is called a
test. The set X = ∪ of all outcomes of
all tests belonging to is called the
outcome space of . Notice that we allow
distinct tests to overlap, i.e., to have outcomes in common.[9]
If
is a test space with outcome-space X, a state on is a mapping ω :
X → [0,1] such that Σx∈E ω(x) = 1
for every test E ∈ . Thus, a state is a
consistent assignment of a probability weight to each test -- consistent in
that, where two distinct tests share a common outcome, the state assigns that
outcome the same probability whether it is secured as a result of one test or
the other. (This may be regarded as a normative requirement on the
outcome-identifications implicit in the structure of : if outcomes of two
tests are not equiprobable in all states, they ought not to be identified.) The
set of all states on is denoted by ω(). This is a
convex set, but in contrast to the situation in discrete classical probability
theory, it is generally not a simplex.
The concept of a random variable admits several generalizations to the
setting of test spaces. Let us agree that a simple (real-valued) random
variable on a test space is a mapping
f : E → R where E is a test in
. We
define the expected value of f in a state ω ∈ ω() in the obvious way,
namely, as the expected value of f with respect to the probability
weight obtained by restricting ω to E (provided, of course, that this
expected value exists). One can go on to define more general classes of random
variables by taking suitable limits (for details, see [Younce, 1987]).
In classical probability theory (and especially in classical statistics) one
usually focuses, not on the set of all possible probability weights, but on some
designated subset of these (e.g., those belonging to a given family of
distributions). Accordingly, by a probabilistic model, I mean pair
(,Δ)
consisting of a test space and a designated set
of states Δ ⊆ ω() on . I'll refer to as the
test space and to Δ as the state space of the model.
I'll now indicate how this framework can accommodate both the usual measure-theoretic formalism of full-blown classical probability theory and the Hilbert-space formalism of quantum probability theory.
be the test space
consisting of all such partitions. Note that the outcome set for is the set X
= B − {Ø} of non-empty Σ-measurable subsets of S. Evidently,
the probability weights on correspond exactly to
the countably additive probability measures on Σ.
denote the collection
of (unordered) orthonormal bases of H. Thus, the outcome-space
X of ∪ will be the unit
sphere of H. Note that if u is any unit vector of
H and E ∈ is any orthonormal
basis, we have
∑x∈E |<u,x>|2 = ||u||2 = 1
Thus, each unit vector of H determines a probability weight
on .
Quantum mechanics asks us to take this literally: any maximal discrete
quantum-mechanical observable is modeled by an orthonormal basis, and any pure
quantum mechanical state, by a unit vector in exactly this way. Conversely,
every orthonormal basis and every unit vector are understood to correspond to
such a measurement and such a state.
Gleason's theorem can now be invoked to identify the states on with the density
operators on H: to each state ω in ω(H) there corresponds a unique density
operator W such that, for every unit vector x of
H, ω(x) = <Wx,x> =
Tr(WPx), Px
being the one-dimensional projection associated with x. Conversely, of
course, every such density operator defines a unique state by the formula above.
We can also represent simple real-valued random variables
operator-theoretically. Each bounded simple random variable f gives
rise to a bounded self-adjoint operator A =
Σx∈E
f(x)Px. The spectral theorem
tells us that every self-adjoint operator on H can be obtained
by taking suitable limits of operators of this form.
,Δ) are several
partially ordered sets, each of which has some claim to the status of an
empirical logic associated with the model. In this section, I'll discuss two:
the so-called operational logic Π() and the property
lattice L(,Δ). Under relatively
benign conditions on , the former is an
orthoalgebra. The latter is always a complete lattice, and under
plausible further assumptions, atomic. Moreover, there is a natural order
preserving mapping from Π to L. This is not generally an
order-isomorphism, but when it is, we obtain a complete orthomodular lattice,
and thus come a step closer to the projection lattice of a Hilbert space.
If
is a test space, an -event is a
set of -outcomes that is
contained in some test. In other words, an -event is simply an
event in the classical sense for any one of the tests comprising . Now, if A
and B are two -events, we say that
A and B are orthogonal, and write
A⊥B, if they are disjoint and their union is again an event.
We say that two orthogonal events are complements of one another if
their union is a test. We say that events A and B are
perspective, and write A~B, if they share any common
complement. (Notice that any two tests E and F are
perspective, since they are both complementary to the empty event.)
4.1 Definition:
A test space
While it is possible to construct perfectly plausible examples of test spaces
that are not algebraic, most test spaces that one encounters in nature --
including the Borel and quantum test spaces described in the preceding section
-- do seem to enjoy this property. The more important point is that, as an
axiom, algebraicity is relatively benign, in the sense that many test spaces can
be completed to become algebraic. In particular, if every outcome has
probability greater than .5 in at least one state, then is contained in an
algebraic test space  having the same
outcomes and the same states as . (See [Gudder, 1985]
for details).
having the same
outcomes and the same states as . (See [Gudder, 1985]
for details).
Suppose now that is algebraic. It is
easy to see that the relation ~ of perspectivity is then an
equivalence relation on the set of -events. More than
this, if is algebraic, then
~ is a congruence for the partial binary operation of
forming unions of orthogonal events: in other words, A~B and
B⊥C imply that A∪C ~
B∪C for all -events A,
B, and C.
Let Π() be the set of
equivalence classes of -events under
perspectivity, and denote the equivalence class of an event A by
p(A); we then have a natural partial binary operation on
Π()
defined by p(A)⊕p(B) =
p(A∪B) for orthogonal events A and
B. Setting 0 := p(Ø) and 1 := p(E),
E any member of , we obtain a
partial-algebraic structure (Π(),⊕,0,1), called the
logic of . This satisfies the
following conditions:
4.2 Definition:
A structure (L,⊕,0,1) satisfying conditions (a)-(d) above is called an orthoalgebra.
Thus, the logic of an algebraic test space is an orthoalgebra. One can show
that, conversely, every orthoalgebra arises as the logic Π() of an algebraic test
space
(Golfin [1988]). Note that non-isomorphic test spaces can have isomorphic
logics.
Any orthoalgebra L is partially ordered by the relation a≤b iff b = a⊕c for some c⊥a. Relative to this ordering, the mapping a→a′ is an orthocomplementation and a⊥b iff a≤b′. It can be shown that a⊕b is always a minimal upper bound for a and b, but it is generally not the least upper bound. Indeed, we have the following [ref]:
4.3 Lemma:
For an orthoalgebra (L,⊕,0,1), the following are equivalent:
- a⊕b = a
- If a⊕b, b⊕c, and c⊕a all exist, then so does a⊕b⊕c
- The orthoposet (L,≤,′) is orthomodular, i.e., for all a, b∈ L, if a≤b then (b
An orthoalgebra satisfying condition (b) is said to be
orthocoherent. In other words: an orthoalgebra is ortho-coherent if and
only if finite pair-wise summable subsets of L are jointly
summable. The lemma tells us that every orthocoherent orthoalgebra is, inter
alia, an orthomodular poset. Conversely, an orthocomplemented poset is
orthomodular iff a⊕b = ab is defined
for all pairs with a≤b′ and the resulting partial binary
operation is associative -- in which case the resulting structure
(L,⊕,0,1) is an orthocoherent orthoalgebra, the canonical
ordering on which agrees with the given ordering on L. Thus,
orthomodular posets (the framework for Mackey's version of quantum logic) are
equivalent to orthocoherent orthoalgebras.
Some version of orthocoherence was taken by Mackey and many of his successors as an axiom. (It appears, in an infinitary form, as Mackey's axiom V; a related but stronger condition appears in the definition of a partial Boolean algebra in the work of Kochen and Specker [1965].) However, it is quite easy to construct simple model test spaces, having perfectly straightforward -- even classical -- interpretations, the logics of which are not orthocoherent. As far as I know, there has never been given any entirely compelling reason for regarding orthocoherence as an essential feature of all reasonable physical models. Moreover, certain apparently quite well-motivated constructions that one wants to perform with test spaces tend to destroy orthocoherence (see Section 7).
The decision to accept measurements and their outcomes as primitive concepts
in our description of physical systems does not mean that we must forgo talk of
the physical properties of such a system. Indeed, such talk is readily
accommodated in our present formalism.[10] In the approach we have been pursuing, a physical
system is represented by a probabilistic model (,Δ), and the system's
states are identified with the probability weights in Δ. Classically,
any subset Γ of the state-space Δ corresponds to a categorical property
of the system. However, in quantum mechanics, and indeed even classically, not
every such property will be testable (or "physical"). (In quantum mechanics,
only subsets of the state-space corresponding to closed subspaces of the Hilbert
space are testable; in classical mechanics, one usually takes only, e.g., Borel
sets to correspond to testable properties: the difference is that the testable
properties in the latter case happen still to form a Boolean algebra of sets,
where in the former case, they do not.)
One way to frame this distinction is as follows. The support of a set of states Γ⊆Δ is the set
S(Γ) = {x∈X | ∃ω∈Γ(ω(x) > 0) }
of outcomes that are possible when the property Γ obtains. There is a sense
in which two properties are empirically indistinguishable if they have the same
support: we cannot distinguish between them by means of a single execution of a
single test. We might therefore wish to identify physical properties with
classes of physically indistinguishable classical properties, or, equivalently,
with their associated supports. However, if we wish to adhere to the programme
of representing physical properties as subsets (rather than as
equivalence-classes of subsets) of the state-space, we can do so, as follows.
Define a mapping F : 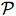 (X) → (Δ) by
F(J) = {ω ∈Δ| S(ω) ⊆ J }. The mapping Γ →
F(S(Γ)) is then a closure operator on (Δ), and the
collection of closed sets (that is, the range of F) is a complete
lattice of sets, closed under arbitrary intersection.[11] Evidently, classical properties -- subsets of Δ --
have the same support iff they have the same closure, so we may identify
physical properties with closed subsets of the state-space:
(X) → (Δ) by
F(J) = {ω ∈Δ| S(ω) ⊆ J }. The mapping Γ →
F(S(Γ)) is then a closure operator on (Δ), and the
collection of closed sets (that is, the range of F) is a complete
lattice of sets, closed under arbitrary intersection.[11] Evidently, classical properties -- subsets of Δ --
have the same support iff they have the same closure, so we may identify
physical properties with closed subsets of the state-space:
4.4 Definition:
The property lattice of the model (
We now have two different logics associated with an entity (,Δ) with algebraic: a logic
Π() of
experimental propositions that is an orthoalgebra, but generally not a lattice,
and a logic L(,Δ) of properties that
is a complete lattice, but rarely orthocomplemented in any natural way (Randall
and Foulis, 1983). The two are connected by a natural mapping [ ] : Π →
L, given by p → [p] =
F(Jp) where for each p∈Π,
Jp = {x∈ X |
p(x) 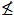 p′ }.
That is, Jp is the set of outcomes that are
consistent with p, and [p] is the largest (i.e., weakest)
physical property making p certain to be confirmed if tested.
p′ }.
That is, Jp is the set of outcomes that are
consistent with p, and [p] is the largest (i.e., weakest)
physical property making p certain to be confirmed if tested.
The mapping p → [p] is order preserving. For both the classical and quantum-mechanical models considered above, it is in fact an order-isomorphism. Note that whenever this is the case, Π will inherit from L the structure of a complete lattice, which will then automatically be orthomodular by Lemma 4.3. In other words, in such cases we have only one logic, which is a complete orthomodular lattice. While it is surely too much to expect that every conceivable physical system should enjoy this property -- indeed, we can easily construct toy examples to the contrary -- the condition is at least reasonably transparent in its meaning.
The answer is: without additional assumptions, not very. The lattice
L(H) has several quite special order-theoretic
features. First it is atomic -- every element is the join of minimal
non-zero elements (i.e., one-dimensional subspaces). Second, it is
irreducible -- it can not be expressed as a non-trivial direct product
of simpler OMLs.[13] Finally, and most significantly, it satisfies the
so-called atomic covering law: if p ∈
L(H) is an atom and p q, then
p q
covers q (no element of L(H) lies
strictly between p q and
q).
These properties do not quite suffice to capture L(H), but they do get us into the right ballpark. Let V be any inner product space over an involutive division ring D. A subspace M of V is said to be ⊥-closed iff M = M⊥⊥, where M⊥ = {v∈V | ∀m∈M( <v,m> = 0)}. Ordered by set-inclusion, the collection L(V) of all ⊥-closed subspaces of V forms a complete atomic lattice, orthocomplemented by the mapping M → M⊥. A theorem of Amemiya and Araki [1965] shows that a real, complex or quaternionic inner product space V with L(V) orthomodular, is necessarily complete. For this reason, an inner product space V over an involutive division ring is called a generalized Hilbert space if its lattice of closed subspaces L(V) is orthomodular. The following representation theorem is due to C. Piron [1964]:
5.1 Theorem:
Let L be a complete, atomic, irreducible orthomodular lattice satisfying the atomic covering law. If L contains at least 4 orthogonal atoms, then there exists an involutive division ring D and an inner-product space V over D such that L is isomorphic to L(V).
It should be noted that generalized Hilbert spaces have been constructed over fairly exotic division rings.[14] Thus, while it brings us tantalizingly close, Piron's theorem does not quite bring us all the way back to orthodox quantum mechanics.
Let us call a complete orthomodular lattice satisfying the hypotheses of Piron's theorem a Piron lattice. Can we give any general reason for supposing that the logic/property lattice of a physical system (one for which these are isomorphic) is a Piron lattice? Or, failing this, can we at least ascribe some clear physical content to these assumptions? The atomicity of L follows if we assume that every pure state represents a "physical property". This is a strong assumption, but its content seems clear enough. Irreducibility is usually regarded as a benign assumption, in that a reducible system can be decomposed into its irreducible parts, to each of which Piron's Theorem applies.
The covering law presents a more delicate problem. While it is probably safe
to say that no simple and entirely compelling argument has been given for
assuming its general validity, Piron [1964, 1976] and others (e.g., Beltrametti
and Cassinelli [1981] and Guz [1980]) have derived the covering law from
assumptions about the way in which measurement results warrant inference from an
initial state to a final state. Here is a brief sketch of how this argument
goes. Suppose that there is some reasonable way to define, for an initial state
q of the system, represented by an atom of the logic/property lattice
L, a final state φp(q) -- either another
atom, or perhaps 0 -- conditional on the proposition p having been
confirmed. Various arguments can be adduced suggesting that the only reasonable
candidate for such a mapping is the Sasaki projection
φp : L → L, defined by
φp(q) = (q p′)
p.[15] It can be shown that an atomic OML satisfies the
atomic covering law just in case Sasaki projections take atoms again to atoms,
or to 0. Another interesting view of the covering law is developed by Cohen and
Svetlichny [1987].
Suppose we are given a statistical model (,Δ). A very
straightforward approach to constructing a "classical interpretation" of (,Δ) would
begin by trying to embed in a Borel test space
, with
the hope of then accounting for the statistical states in δ as averages over
"hidden" classical -- that is, dispersion-free -- states on the latter. Thus,
we'd want to find a set S and a mapping X → (S) assigning
to each outcome x of a set
x* ⊆ S in such a way that, for each test E ∈ ,
{x* | x ∈ E} forms a partition of S. If this
can be done, then each outcome x of simply records the
fact that the system is in one of a certain set of states, namely, x*.
If we let Σ be the Σ-algebra of sets generated by sets of the form {x*
| x ∈ X}, we find that each probability measure μ on Σ pulls
back to a state μ* on , namely,
μ*(x) = μ(x*). So long as every state in δ is of this form, we
may claim to have given a completely classical interpretation of the model (,Δ).
The minimal candidate for S is the set of all
dispersion-free states on . Setting x*
= {s∈S | s(x) = 1} gives us a classical
interpretation as above, which I'll call the classical image of . Any other
classical interpretation factors through this one. Notice, however, that the
mapping x → x* is injective only if there are sufficiently
many dispersion-free states to separate distinct outcomes of . If has no
dispersion-free states at all, then its classical image is empty.
Gleason's theorem tells us that this is the case for quantum-mechanical models.
Thus, this particular kind of classical explanation is not available for quantum
mechanical models.
It is sometimes overlooked that, even if a test space does have a
separating set of dispersion-free states, there may exist statistical states on
that
can not be realized as mixtures of these. The classical image provides
no explanation for such states. For a very simple example of this sort of thing,
consider the the test space:
and the state ω(a) = ω(b) = ω(c) = ½,
ω(x) = ω(y) = ω(z) = 0. It is a simple exercise to
show that ω cannot be expressed as a weighted average of {0,1}-valued states on
. For
further examples and discussion of this point, see Wright [1980].]
The upshot of the foregoing discussion is that most test spaces can't be
embedded into any classical test space, and that even where such an embedding
exists, it typically fails to account for some of the model's states. However,
there is one very important class of models for which a satisfactory classical
interpretation is always possible. Let us call a test space
semi-classical if its tests do not overlap; i.e., if E ∩
F = Ø for E, F ∈ , with
E≠F.
6.1 Lemma:
Let
As long as is locally countable
(i.e., no test E in is uncountable),
every state can be represented as a convex combination, in a suitable sense, of
extreme states [Wilce, 1992]. Thus, every state of a locally countable
semi-classical test space has a classical interpretation.
Even though neither Borel test spaces nor quantum test spaces are
semi-classical, one might argue that in any real laboratory situation,
semi-classicality is the rule. Ordinarily, when one writes down in one's
laboratory notebook that one has performed a given test and obtained a given
outcome, one always has a record of which test was performed. Indeed, given any
test space , we may always form a
semi-classical test space simply by forming the co-product (disjoint union) of
the tests in . More formally:
6.2 Definition:
For each test E in
= {E~ | E ∈
We can regard as arising from
by deletion of the record of which test was performed to secure a given outcome.
Note that every state on defines a state ω̃ on
by
ω̃(x,E) = ω(x). The mapping ω → ω̃ is plainly
injective; thus, we may identify the state-space of with a subset of the
state-space of . Notice that
there will typically be many states on that do
not descend to states on . We might wish to
think of these as "non-physical", since they do not respect the (presumably,
physically motivated) outcome-identifications whereby is defined.
Since it is semi-classical, admits a
classical interpretation, as per Lemma 7.1. Let's examine this. An element of
S() amounts to a
mapping f : → X,
assigning to each test E ∈ , an outcome
f(E) ∈ E. This is a (rather brutal) example of what
is meant by a contextual (dispersion-free) hidden variable. The
construction above tells us that such contextual hidden variables will be
available for statistical models quite generally. For other results to the same
effect, see Kochen and Specker [1967], Gudder [1970], Holevo [1982], and, in a
different direction, Pitowsky [1989].[16]
Note that the simple random variables on correspond exactly to
the simple random variables on , and that
these, in turn, correspond to some of the simple random variables (in
the usual sense) on the measurable space S(). Thus, we have
the following picture: The model (,Δ) can always be
obtained from a classical model simply by omitting some random variables, and
identifying outcomes that can no longer be distinguished by those that
remain.
All of this might suggest that our generalized probability theory presents no significant conceptual departure from classical probability theory. On the other hand, models constructed along the foregoing lines have a distinctly ad hoc character. In particular, the set of "physical" states in one of the classical (or semi-classical) models constructed above is determined not by any independent physical principle, but only by consistency with the original, non-semiclassical model. Another objection is that the contextual hidden variables introduced in this section are badly non-local. It is by now widely recognized that this non-locality is the principal locus of non-classicality in quantum (and more general) probability models. (For more on this, see the entry on the Bell inequalities.)
A particularly striking result in this connection is the observation of
Foulis and Randall [1981] that any reasonable (and reasonably general) tensor
product of orthoalgebras will fail to preserve ortho-coherence. Let 5
denote the test space
{{a,x,b}, {b,y,c}, {c,z,d}, {d,w,e}, {e,v,s}}
consisting of five three-outcome tests pasted together in a loop. This test
space is by no means pathological; it is both ortho-coherent and algebraic.
Moreover, it admits a separating set of dispersion-free states and hence, a
classical interpretation. Now consider how we might model a compound system
consisting of two separated sub-systems each modeled by 5. We would
need to construct a test space and a mapping 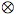 :
X × X → Y = ∪ satisfying,
minimally, the following;
:
X × X → Y = ∪ satisfying,
minimally, the following;
z ⊥
yz and
zx ⊥
zy,
5), there
exists at least one state ω on such that
ω(xy) =
α(x)β(y), for all outcomes x, y ∈
X. Foulis and Randall show that no such embedding exists for which is orthocoherent.
Another result having a somewhat similar force is that of Aerts [1982]. If L1 and L2 are two Piron lattices, Aerts constructs in a rather natural way a lattice L representing two separated systems, each modeled by one of the given lattices. Here "separated" means that each pure state of the larger system L is entirely determined by the states of the two component systems L1 and L2. Aerts then shows that L is again a Piron lattice iff at least one of the two factors L1 and L2 is classical. (This result has recently been strengthened by Ischi [2000] in several ways.)
The thrust of these no-go results is that straightforward constructions of plausible models for composite systems destroy regularity conditions (ortho-coherence in the case of the Foulis-Randall result, orthomodularity and the covering law in that of Aerts' result) that have widely been used to underwrite reconstructions of the usual quantum-mechanical formalism. This puts in doubt whether any of these conditions can be regarded as having the universality that the most optimistic version of Mackey's programme asks for. Of course, this does not rule out the possibility that these conditions may yet be motivated in the case of especially simple physical systems.
| Alexander Wilce wilce@susqu.edu |
A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z